训练营课程介绍
机器学习&数据工程全栈项目班
大数据行业深度学习+团队合作项目+实习推荐机会
- 澳洲第一个面向企业的数据工程师培训,掌握大数据整个流程
- 通过三个项目加强数据工程技术栈学习,个人项目+团队项目
课程顾问
查看 AI 职业影响地图 →课程预览
Upcoming
近期开课
可以插班
机器学习全栈班第17期
2026/01/25|Online|Online
$5,000
可以插班
机器学习全栈班第16期
2025/04/13|Online|Online
$5,000
可以插班
数据工程全栈班第15期
2024/10/13|Online|Online
$5,000
我们的机器学习&数据工程全栈项目班校友现在工作在






Core Features
机器学习&数据工程全栈项目班亮点
01
3个项目经验丰富你的简历,2 个个人项目+1 个团队大项目,简历内容远超同龄人
02
成为起薪80k的大数据工程师,迎接岗位需求量巨大的大数据时代
03
结合AWS+DevOps,AWS云技术与DevOps Engineer配合,加强你的工程化能力
04
导师+Tutor答疑团为你保驾护航,Lecture+Tutorial授课模式,导师和Tutor全程答疑,深度挖掘数据工程内容
JOB-READY PORTFOLIO
每期不同的商业团队项目向招聘企业展示
多位Data Engineer合作,从需求分析做起,一直到数据处理,数据架构搭建,机器建模和可视化。学习如何在AWS云上搭建数据库以及数据流程,用大数据工具处理和转换数据,分析数据和搭建模型,最后把项目产品化并创造价值。
团队项目数:2+

商业数据工程全栈班第11期 项目展示:Ori-Arrow

数据工程全栈班第13期 项目展示:Data Magic
Student Stories
学员采访 · 学长学姐的逆袭之路
Curriculum
机器学习&数据工程全栈项目班课程大纲
注册即可免费体验真实学习环境
1数据工程基础6 课时
ℹ️Preparation Checklist免费试学信息
👨🏫数据工程17期开课讲解会辅导
ℹ️Big Data Introduction免费试学信息
🎬Structured Data vs Unstructured Data视频
🎬Linux 基础视频
🎬Git 的基本使用视频
2Extract 阶段10 课时
📚数据工程概述免费试学课程
🎬Python 文件操作与数据格式视频
📚非稳定数据源抽取:API 抽取与工程化设计课程
📚Extract:抽取概览 + Raw 层设计(ETL)课程
ℹ️Vibe Coding入门信息
📚AI Coding 最佳实践课程
🎬DE Introduction & DBMS - Relational Model视频
📚Extract结构化数据抽取:文件与数据库数据如何安全进入系统?课程
🎬Working With API - Pre-Extract Knowledge视频
👨🏫Tutorial辅导
3云计算和数据工程21 课时
🎬AWS Basics免费试学视频
📚Databases on AWS课程
📚Data engineering Practice课程
👨🏫在 AWS 上 SQL 操作辅导
ℹ️Private Project Introduction信息
🎬"时间序列分析与 Pandas:从数据处理到 ARIMA 预测"视频
🎬AWS Permission & IAM & S3视频
🛠️AWS IAM 的基本用法和高级使用工作坊
🎬AWS Computing视频
👨🏫AWS Lambda辅导
🎬Unix/Linux Shell 基础 × Data Warehouse核心建模视频
🎬Docker 的使用视频
ℹ️GitHub Actions Setup信息
🎬AWS Messaging视频
🎬AWS Messaging02视频
🎬AWS Networking视频
🛠️AWS Lambda基础知识和Serverless概念工作坊
🎬AWS VPC视频
📚AWS data platform and serverless part 1课程
📚AWS data platform and serverless part 2课程
👨🏫Serverless辅导
4数据处理技术5 课时
🎬Database 与 SQL 基础视频
🎬DBMS & SQL Intro视频
🎬SQL 基础视频
🎬SQL Part1视频
🎬SQL Part2视频
5团队商业项目15 课时
🎬什么是代码的SOLID原则视频
📚Data Lake and Architecture on AWS课程
📚Group project bootstrap课程
ℹ️Group Project Intro信息
🛠️Workshop: 持续集成(CI)/持续部署(CD)的概念以及Jenkins的使用工作坊
📚Group Project Proposal课程
📚Big data processing and modelling课程
✏️Project Assignment 2作业
👨🏫Machine Learning辅导
👨🏫Deployment辅导
📚Data Streaming: Kafka& Kinesis课程
👨🏫Streaming辅导
🛠️前端 后端 API入门介绍工作坊
🛠️数据工程师可以了解的Dev知识工作坊
📚Group Project Presentation课程
6AI Engineer Basics7 课时
📚AI Data Engineering: Embedding & Vector Database课程
🎬AI Basics视频
📚Introduction to LLM & RAG for Recommendations课程
👨🏫RAG项目实操辅导
📚AI Data Engineering: Text to SQL课程
🎬AI for Data Analysis&Azure AI Services Overview视频
🎬AI数据分析实操:Copilot视频
7数据模型和数据仓库1 课时
📚Data Warehouse & Data Lake课程
8Big Data4 课时
🎬Big Data: HDFS视频
📚Spark SQL & Dataset课程
👨🏫Spark Tutorial辅导
🎬CI/CD and Orchestration with Airflow and dbt视频
9Machine Learning8 课时
📚Machine Learning Basics课程
🎬Supervised, Unsupervised, and Reinforcement learning视频
🎬Advanced Machine Learning视频
🎬Introduction to Machine Learning视频
📚Machine Learning Model Evaluation & Fine-Tuning课程
🎬Python Machine Learning Part1视频
🎬Python Machine Learning Part2视频
📚Machine Learning Model Deployment课程
10数据可视化工具2 课时
🎬Data visualization with Tableau视频
🎬Data Analytics视频
11项目实战1 课时
✏️Assignment 3作业
12数据安全与隐私保护1 课时
🎬Data Security&Dynamic Data Masking视频
13Agile项目管理4 课时
🎬Agile Methodologies视频
🎬Agile Scrum视频
🎬什么是Agile SDLC, Waterfall, Agile介绍视频
🎬Agile Case研究:微软Microsoft Case Study视频
14IT Career Coaching10 课时
🎬Resume and Interview视频
🎬Linkedin & CV视频
🎬澳洲工作职场介绍视频
🎬澳洲企业招聘流程视频
🎬招聘官挑选简历的标准视频
🎬如何撰写 IT 专业简历视频
🎬简历常见问题视频
🎬如何利用 ChatGPT 写简历视频
🎬手把手带着运营 LinkedIn视频
🎬如何利用 LinkedIn 准备面试视频
Why DevOps
为什么选择机器学习&数据工程全栈项目班
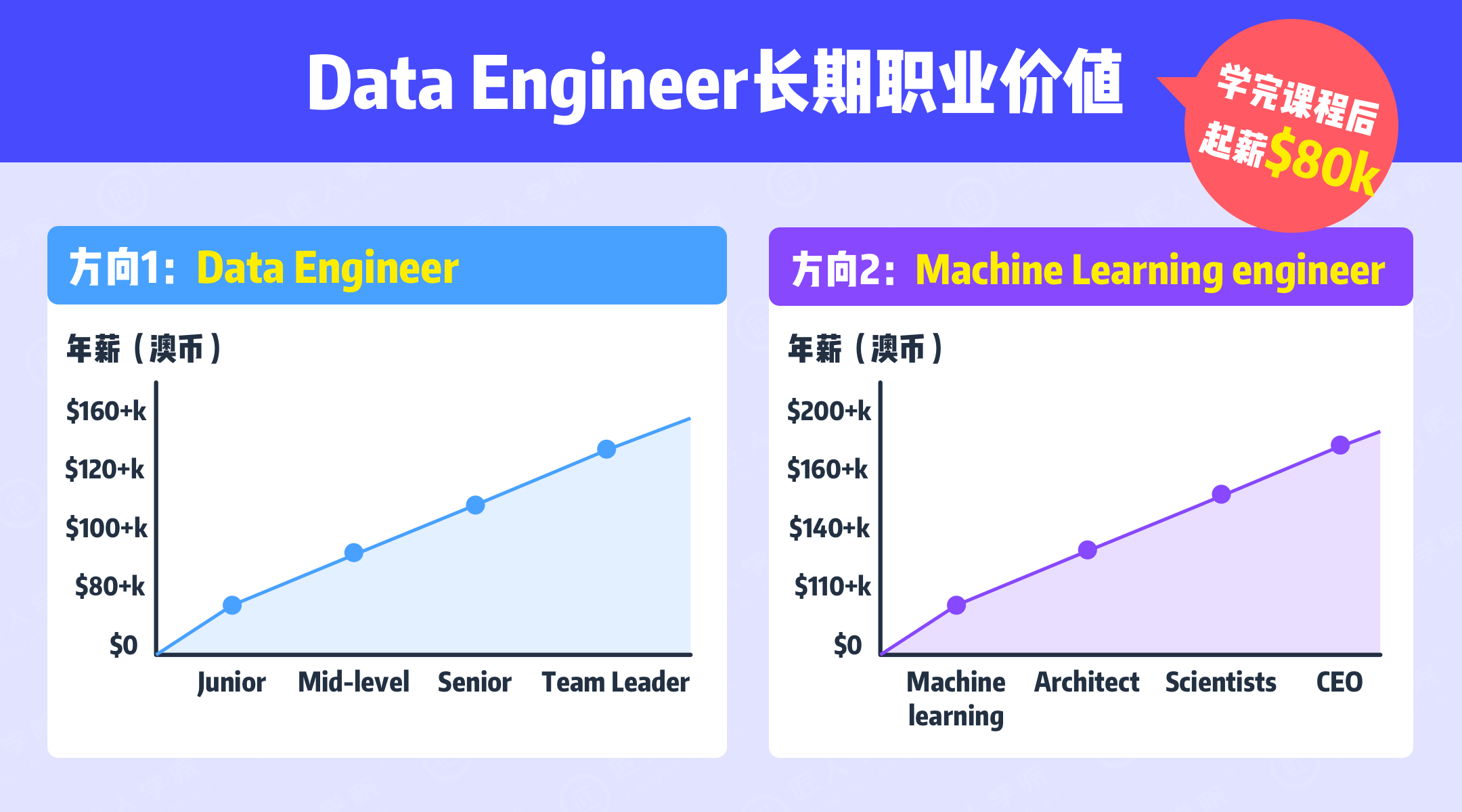
行业洞察大数据是眼下非常时髦的技术名词,随着大数据产业链的不断完善以及大数据本身价值在被不断地开发,数据方面的岗位不论在哪都有巨大的用人需求。根据澳洲最大的求职网站Seek统计,即使在疫情期间,Data Engineer仍然有4000+的职位虚位以待。作为一个高技术、高需求的新行业,数据工程师在澳洲的平均工资甚至达到了120k+。 ...
Expert Team
导师团队



价格选项
100+ 小时导师直播授课
丰富的视频课程辅助学习
3 个项目丰富简历
80+ Career Coaching Self-paced Learning课程
可以插班
机器学习全栈班第17期
2026/01/25
课程时长:
授课方式:Online
授课地点:Online
授课老师:Leo, Gucheng Zhu, Jevy, Chao Mu , Chris WANG, Eric Xi, HUILIAN GU, Xi Gong, Jenny LIN, Allen Chen, Xiao Hua, 匠人小班 Beta, Lightman Wang, beta beta, Huansong(Winston) Zeng, Liangjun Song
可以插班
机器学习全栈班第16期
2025/04/13
课程时长:
授课方式:Online
授课地点:Online
授课老师:Leo, Gucheng Zhu, Chao Mu , Jevy, Ray Ma, Eric Xi, Lightman Wang, Allen Chen, Xi Gong, HUILIAN GU, Xiao Hua, 匠人小班 Beta, Yolanda Yang, Yuhan Li, Jenny LIN, Chris WANG
可以插班
数据工程全栈班第15期
2024/10/13
课程时长:
授课方式:Online
授课地点:Online
授课老师:Leo, Gucheng Zhu, Chao Mu , Jevy, Yuhan Li, 匠人小班 Beta, Yolanda Yang, Xiao Hua, Ray Ma, Eric Xi, William Zheng, Lightman Wang, Allen Chen, Xi Gong, HUILIAN GU
分期支付 $ 1054 X 6 = $ 6324
*Taxes are applicable
首付$ 695 分期支付$ 521 X 12 = $ 6252
*Taxes are applicable
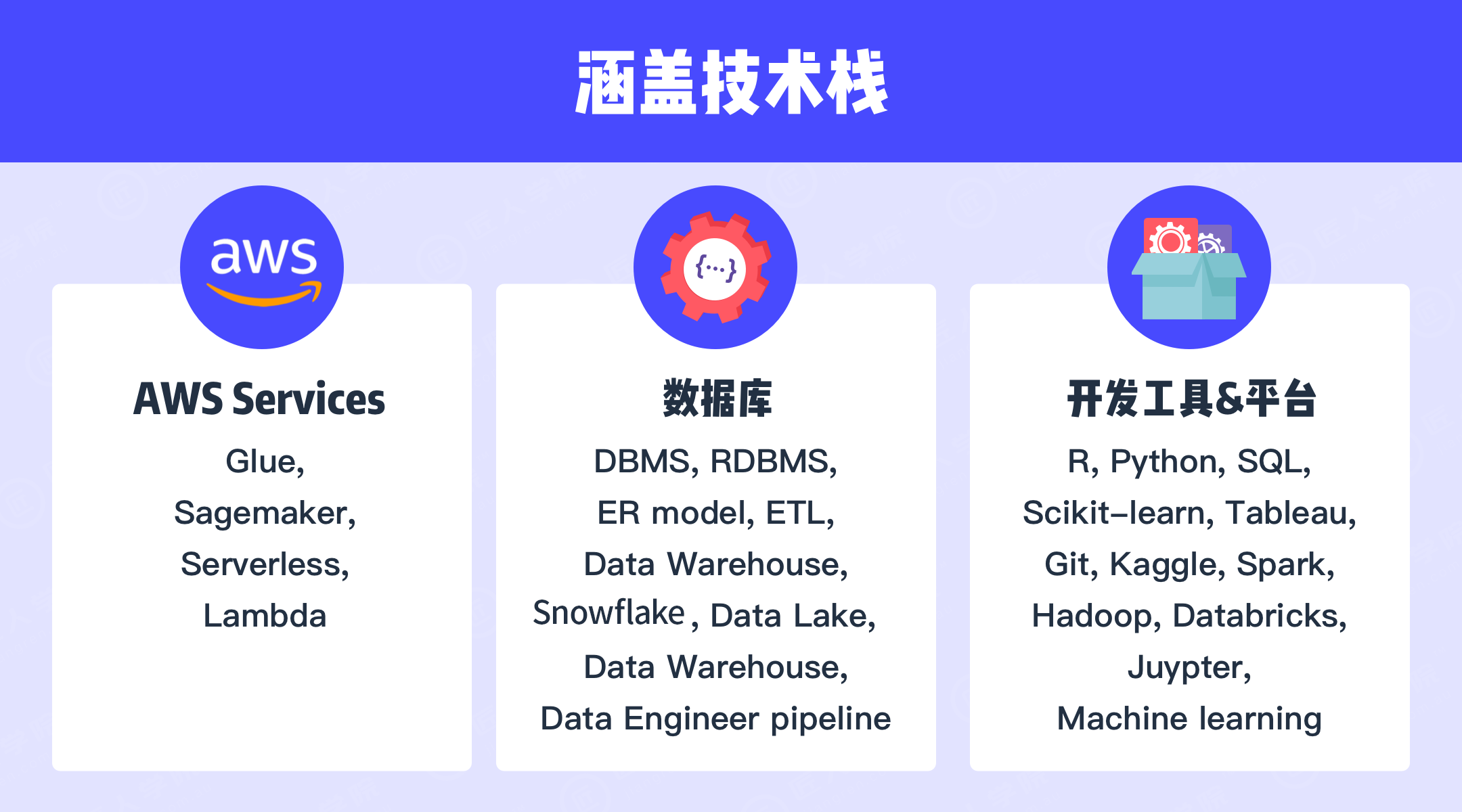
Tech Stack
课程知识点
数据全栈
DBMS
ER Model
Snowflake
AWS
Data Engineering Pipeline
Data Wrangling
Python
Jupyter
Pandas
Power BI
SQL
Agile
Prototype
Linux
Machine Learning
Statistical Modelling
Exploratory Data Analysis
XGBoost
Data Visualisation
Spark
Hadoop
Git
Datalake
Kaggle
Scikit Learn
Databricks
Data Warehouse
Tableau
R
ETL
AWS-云大数据
AWS EC2
AWS S3
AWS RDS
Redshift
AWS Lambda
AWS VPC
Cloudformation
AWS Athena
AWS Glue
Step Functions
AWS Sagemaker
AWS SQS
AWS SNS
Serverless
AI Engineering
Retrieval Augmented Generation (RAG)
Prompting
Embeddings
Vector Database
LLM
Qdrant
Target Audience
谁应该参加我们的机器学习&数据工程全栈项目班?
IT/CS 在校生、毕业生
DS 在校生、毕业生
IS 毕业生
想从事数据工程的数据分析师
课程详情Course Detail
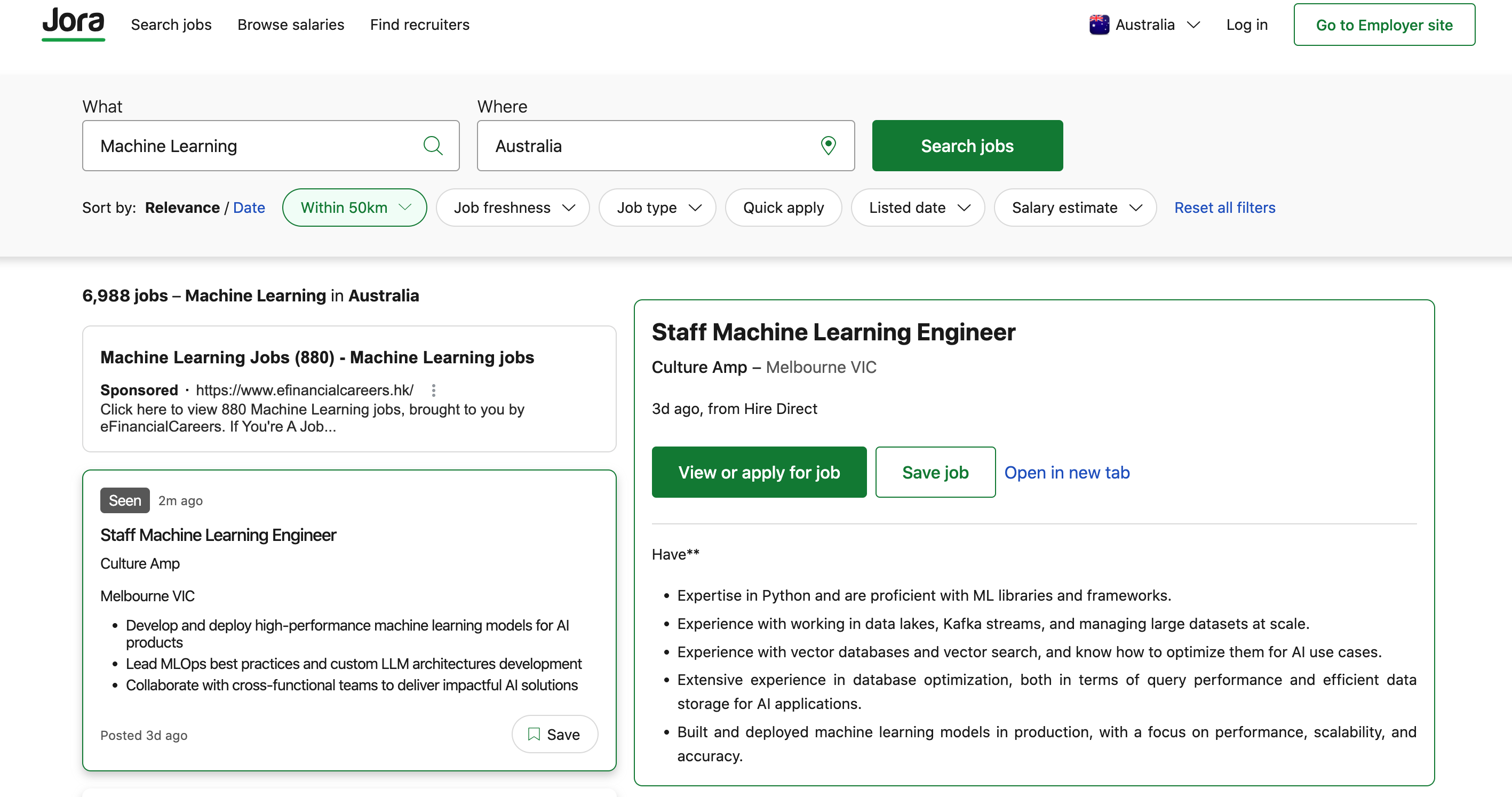
在Gen AI 高速发展的今天,数据工程师的角色正在发生深刻转变。企业不再满足于“搬数据、管流程”的传统数据处理能力,而是更需要既懂数据架构、又能对接 AI 模型,具备全链路“数据→智能”交付能力的新一代全栈数据工程师、ML Engineer。目前澳洲的机器学习工程师岗位需求非常旺盛,共有超过 300 个职位在 Indeed 网站上发布。Jora 网站列出了超过 5,400 个相关职位,薪资范围从每年 10 万美元(约 145,000 澳元)到 20 万美元(约 290,000 澳元)不等,取决于经验和职位。
为顺应行业趋势,我们在原有“数据工程 + 大数据 + 云计算”体系上,重磅升级了 Machine Learning 与 AI 应用模块,推出全新 7.0 课程体系。
新升级课程,全面融合 Machine Learning 和 Retrieval-Augmented Generation (RAG) 全流程实战技术,上手 AI 领域最前沿的解决方案!
新升级的课程也适合留学生回国就业
课程升级的必要性
岗位需求变化:澳洲与全球主流科技公司纷纷在数据平台团队中引入 ML Engineer / LLM Integrator / Data Product Owner 等新型混合岗位
工具与平台演进:SageMaker、Qdrant、OpenAI API、LangChain 等新工具成为团队必备能力
项目场景升级:从传统可视化报表 → 实时数据驱动 → 智能问答与推荐,数据系统正走向 AI 化、服务化
课程也能满足澳洲留学生回国就业所需技能,国内阿里、字节跳动、腾讯、科大讯飞等大厂都在大力招聘机器学习工程师
课程大纲升级亮点解析
引入完整 Machine Learning 流程教学:从算法到部署,掌握企业级模型训练管道
新增 RAG 架构实战模块:打造真实场景下的智能问答与推荐系统,使用向量数据库 + LLM 构建语义搜索引擎
全面覆盖 AI+DE 全链路技术体系:从数据存储、数据处理、ML建模到 AI 应用开发,一站式掌握职场刚需技能
三个月学习+项目实战,全方位成为 AI 时代的数据工程师
课程培养学员具备数据工程技术、大数据处理、AWS、Machine Learning和Gen AI 实战能力,帮助学员打通从数据存储、模型训练到应用部署的全链路技术思维。
课程大纲7.0三大新升级
✨ 新增 1: Machine Learning 全流程实战
全面融合算法技术和实际应用,包括:
ML基础算法:Linear Regression,Logistic Regression,Decision Tree,Random Forest,KMeans Clustering,SVM,Naive Bayes
用 Spark MLlib 实现分类/聚类算法,处理分布很大的数据量
使用 OpenAI Embedding 生成文本向量,实现文本分类/搜索/推荐
AWS SageMaker 上训练、模型部署和 Endpoint API 接入
搭建自己的机器学习 Web App,支持推荐、预测、分析功能
✨ 新增 2: AI RAG (检索增强生成) 架构实战
完整实战系列,打造可部署的智能推荐和问答系统:
实战课程:Introduction to LLM & RAG for Recommendations
介绍 LLM 与 RAG 核心模型和工作原理,分析与传统推荐系统的区别
数据准备:标准化产品列表,数据清洗,产品描述 embedding
向量库选型和实现:Qdrant 搭建向量搜索基础,支持快速相似度检索
构建全流程 RAG 系统:问题向量化,文档搜索,上下文组装,LLM生成,Post-processing 输出
搭建对话界面:使用 Streamlit/前端框架实现应用结果输出
容器化部署:使用 Docker 部署整套服务,包括前端+API+Qdrant
✨ 新增 3: AI+DE 联合项目实战
进入「AI智能项目培成模块」,综合运用云服务、数据建模、RAG和LLM能力,完成端到端 AI 应用实战
实现基于 LLM API 的人工智能问答/分析应用
基础步骤 + 项目实战 + 就业资源,一路打通
第一阶段:数据工程基础矩阵
Python 基础、Linux 命令行、Git/Github CI/CD 组织合作
数据格式、数据清洗、SQL 高级经典操作
数据存储: PostgreSQL 和问卷数据库,数据模型设计
数据存储和搜索: Data Warehouse (Redshift), Data Lake (S3)
ETL 流程:Airflow + Python 实现数据投入、处理、删重
第二阶段:大数据 & 云服务技术
Spark 分析大数据、完成处理、聚类、分类算法
AWS Glue 、Athena、Lambda、EC2 等云上组件实战使用
云上管道搭建和规范化管理
第三阶段:AI技术入门 + 实战化项目
同步进入 ML 算法 + LLM API + RAG 项目培成
项目包括智能推荐、云部署分析、自动化管道、Docker部署
学员最终成果可以搭建一套自己的 AI+DE 数据系统
第四阶段:简历打造 + 内推资源
专业项目评估、简历打造、行业环境解析
全系列 Career Coaching 课程,包括职业计划、面试技巧、谈薪技巧
学员项目补充和内推机会优先排序
什么是数据工程?
数据工程是指面向不同计算平台和应用环境,使用信息系统设计,开发和评价的工程化技术和方法,一般被广泛应用于数据的传输,转换和储存。像如何高效存储海量的数据,利用实时数据反馈用户状况,以及利用机器学习来实现精准推荐等都是数据工程所研究的方向。

什么是数据工程师?
数据工程师在大数据时代或者被称为数据架构师更准确,工作的重点更偏向于数据架构,计算,数据存储,数据流,数据库设计等方向。因此数据工程师会对编程要求更高一点。
数据工程师的工作内容
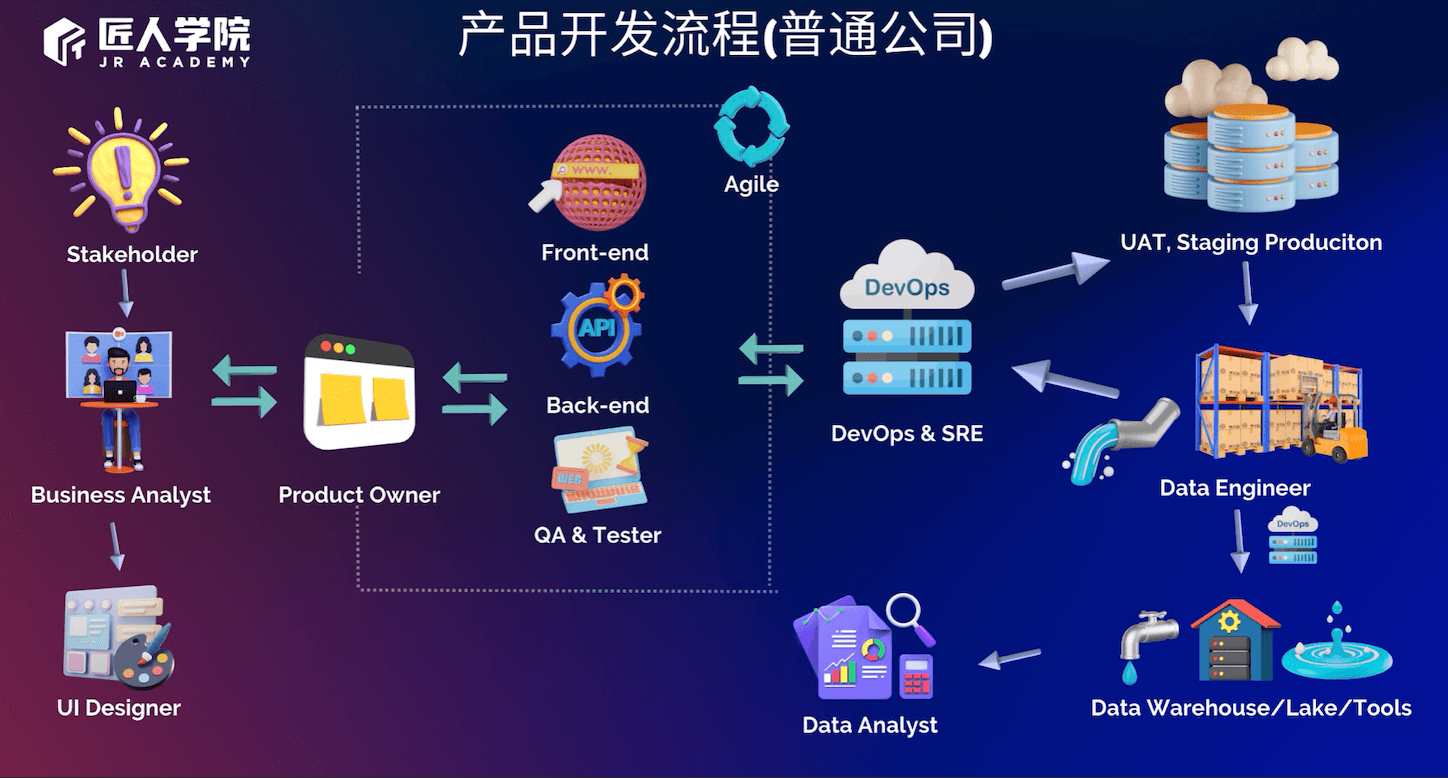
数据工程师就像餐厅的主厨一样,为了给大家呈现精美的菜肴,首先需要进货,购买一些蔬菜和鸡鸭鱼肉,而这些原始食材就相当于source data一样。
当通过不同的方式得到原数据后,DE需要通过各种方式处理好这些数据,就类似厨师需要给鱼刮刮鳞,鸡要去毛,肉要腌制等;初步处理完毕后,还要把各种食材切成不同的形状,所有这些食物材料的处理,就相当于data transformation和data cleansing。
食材处理完毕后,需要烹饪成菜肴,比如说有些菜需要蒸,有些菜需要炸,那么厨师就会以相应的方式去烹饪这道菜,这就类似于数据工程中有时候需要处理好的数据以dashboard的形式去展现出,有时候需要用处理好的数据去训练ML的model。
有些时候,处理好的数据不需要立刻做成菜肴,那么厨师就会把这些食材放进冰箱,这就相当于数据工程中的data backup操作 - 把处理好的数据先backup到某个地方,之后有product需要这些处理好的数据时,再拿出来用。
从原食材到最终呈现给顾客的这整个过程,就相当于把源数据变为数据产品的整个过程。作为主厨,还需要通过不同的方式,去收集食客的反馈,才可以改进菜肴的味道,这相当于在数据工程中,收集用户的反馈,并根据反馈来改进各个环节的数据操作。
数据工程师 DE vs 数据分析师 DA vs 数据科学家 DS
数据分析师主要是负责收集处理数据以及对数据进行可视化展示,而数据工程师更多负责搭建数据结构,以及大量使用云技术与 DevOps 合作进行云端环境的搭建。数据科学家则对更注重于数据模型,机器学习以及数据挖掘等方面。

为什么要学数据工程?
而且由于数据需要长期维护,所以数据工程师工作相对稳定,但是无论是在澳洲还是在中国都没有一个完善的培养机制,通过培训的数据工程师会相对更受青睐。
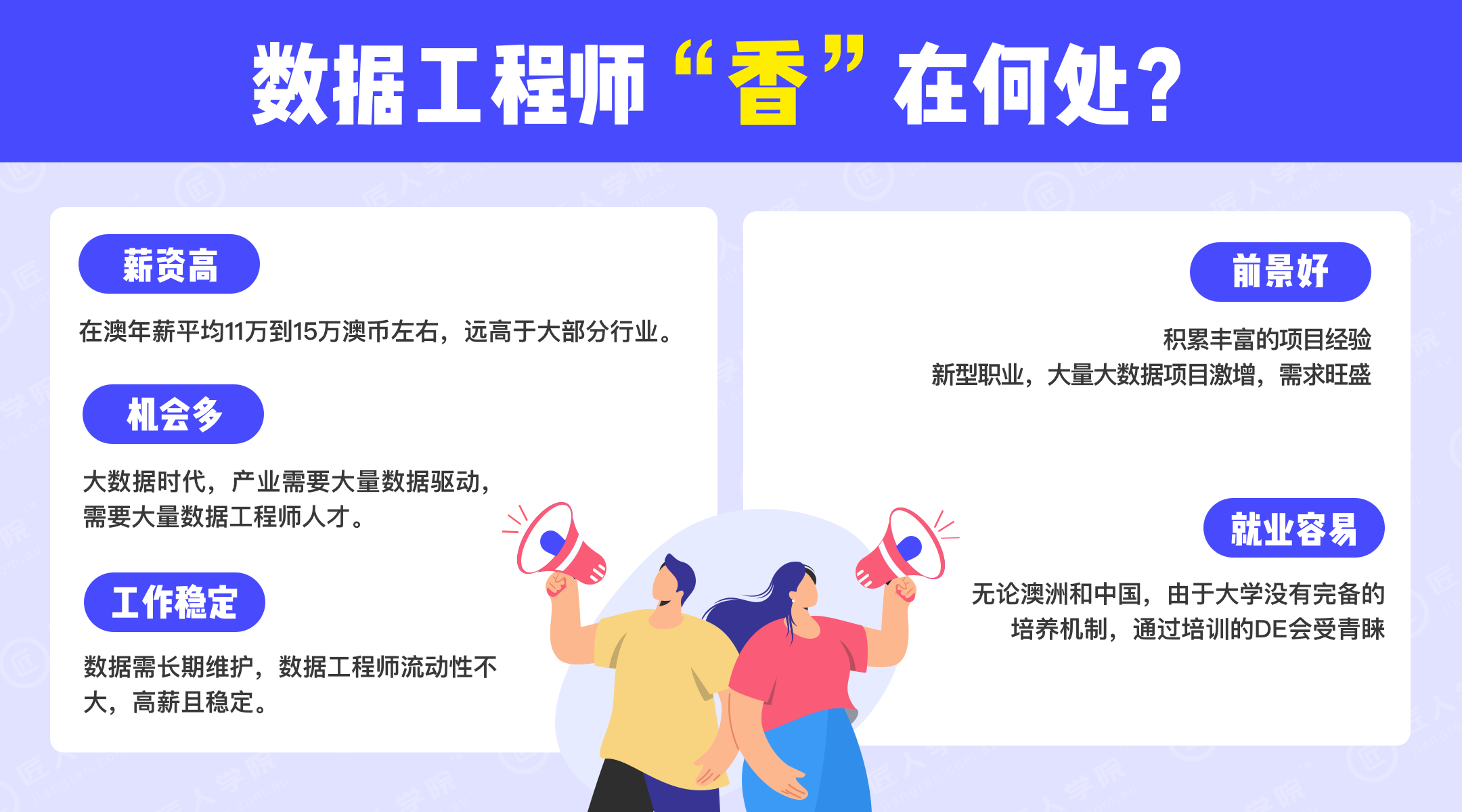
什么是数据工程全栈项目班?
匠人学院的数据工程全栈项目班是全澳首创的大数据培训课程,已经帮助数百位学员拿到Offer,课程由一线大厂导师结合匠人独特的培训5.0模式(直播授课+真实团队项目)来培养出技术过硬,以及有丰富实战经验的数据工程师。并且学生在两年内可以免费重听,享受终身视频免费学习。
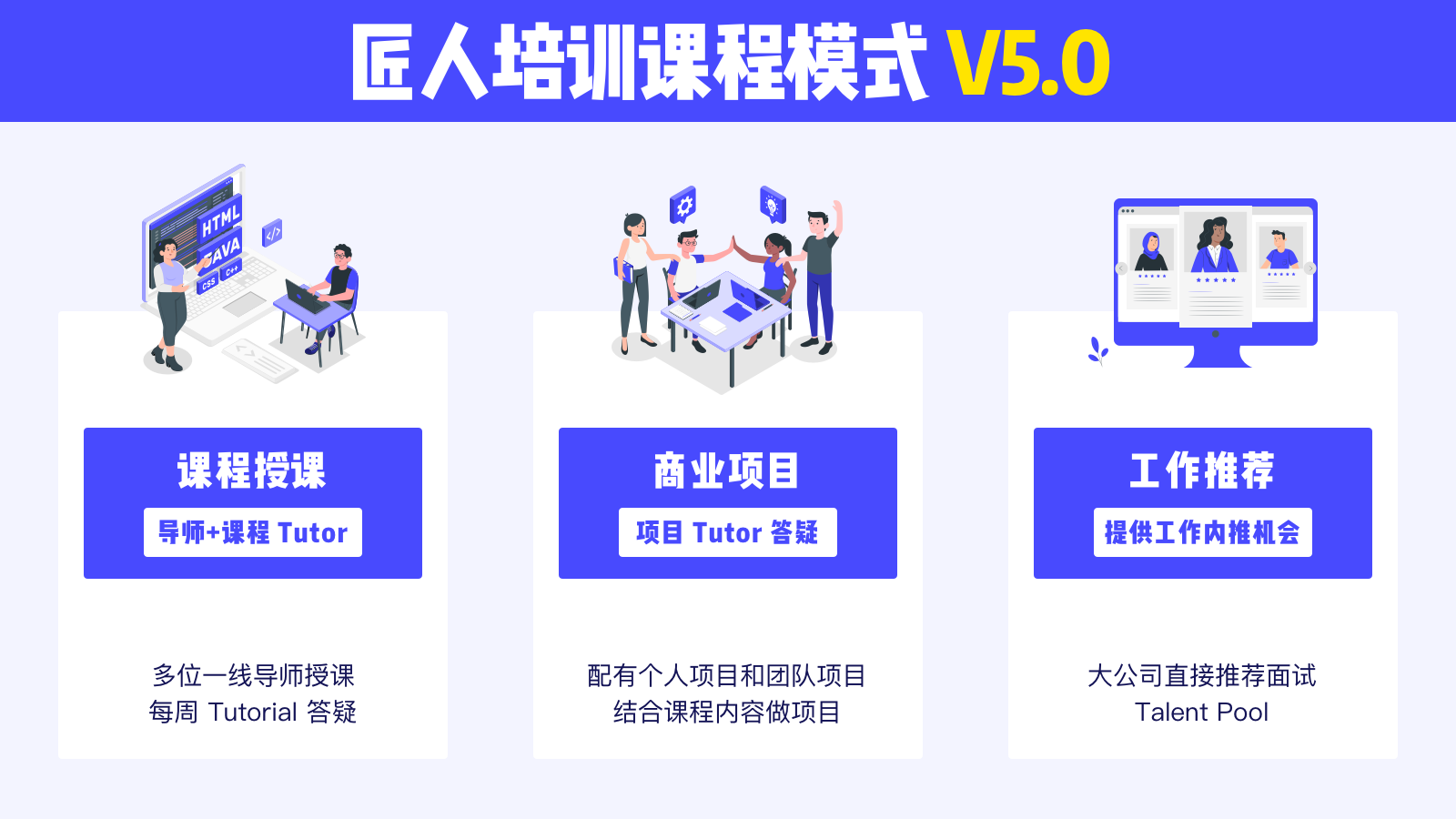
在三个月内,一线大厂导师进行线上授课,为同学答疑解惑,让学生系统地掌握数据工程师的核心技术技能。除此之外,学生还会完成一个独立的个人项目及一个与 DevOps 合作的多角色团队大项目,将所学知识点应用于项目实战中去。
课程会主要分为基础知识学习,数据项目实战以及公司商业项目、简历内推三大阶段来提升学生个人能力,完美模拟真实工作内容及流程。
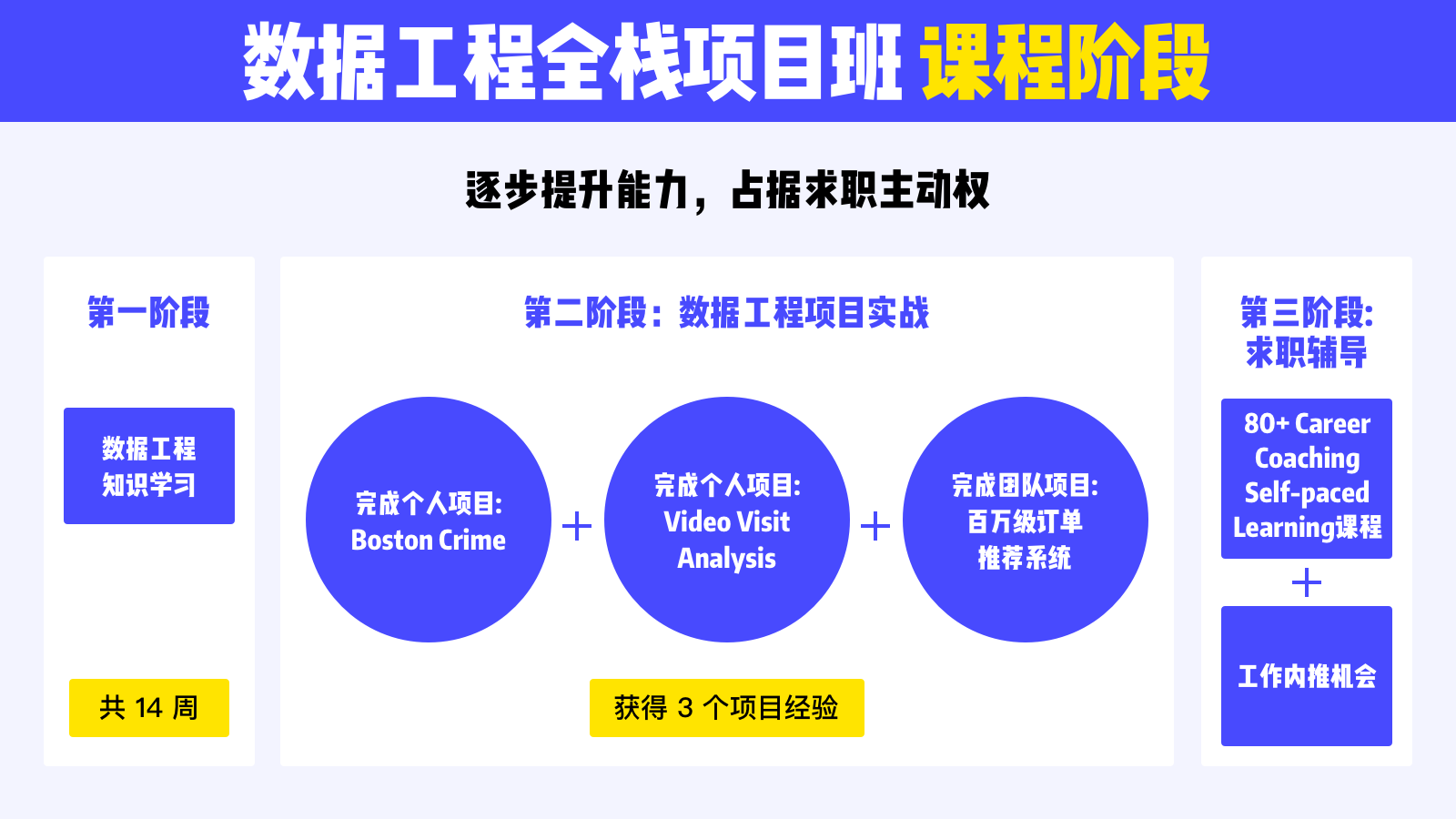
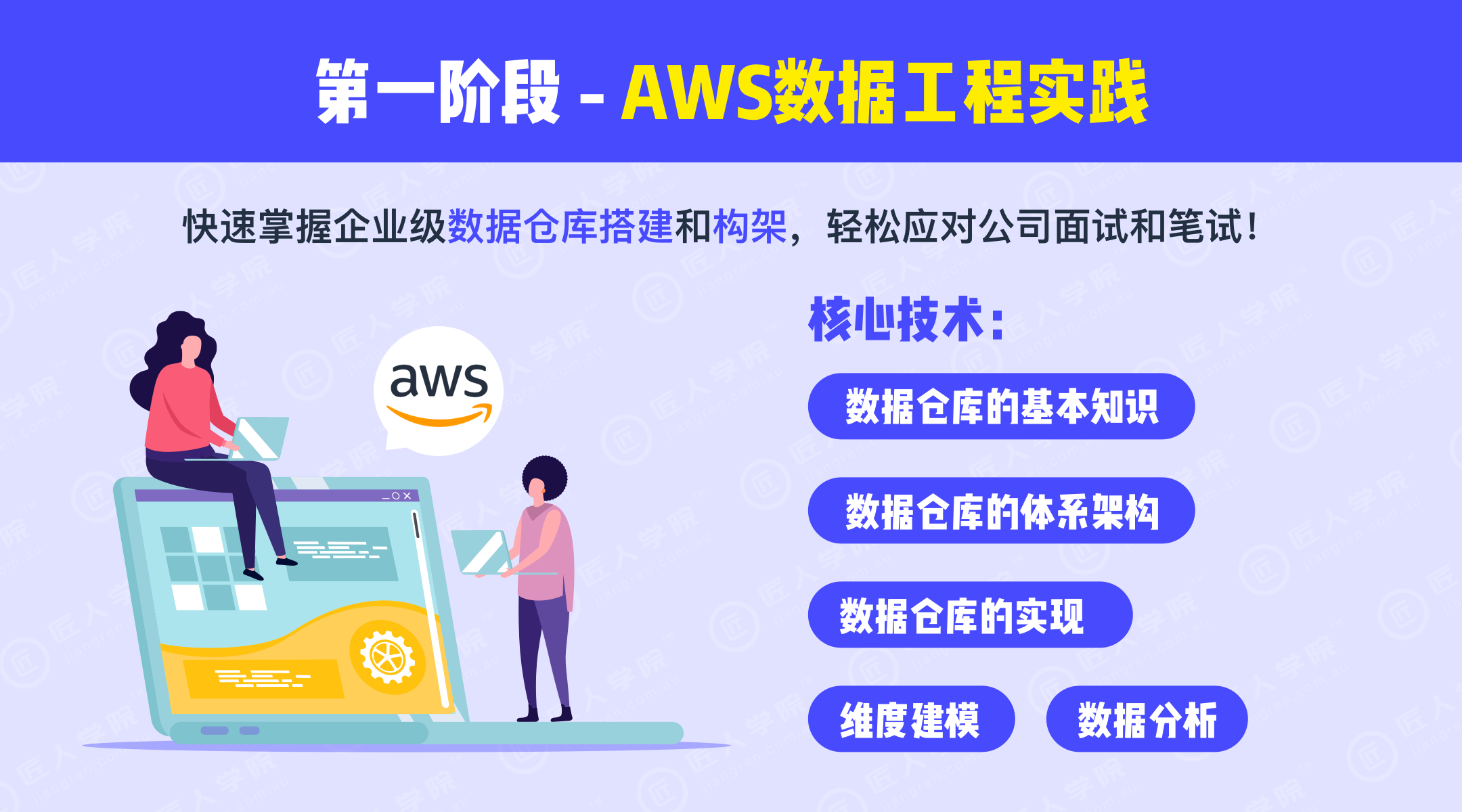
第一阶段:数据基础知识学习
一线大厂明星导师进行直播授课,系统进行数据工程核心技术的知识讲解,带领学生快速掌握企业级数据仓库搭建和构架,轻松应对公司面试和笔试。
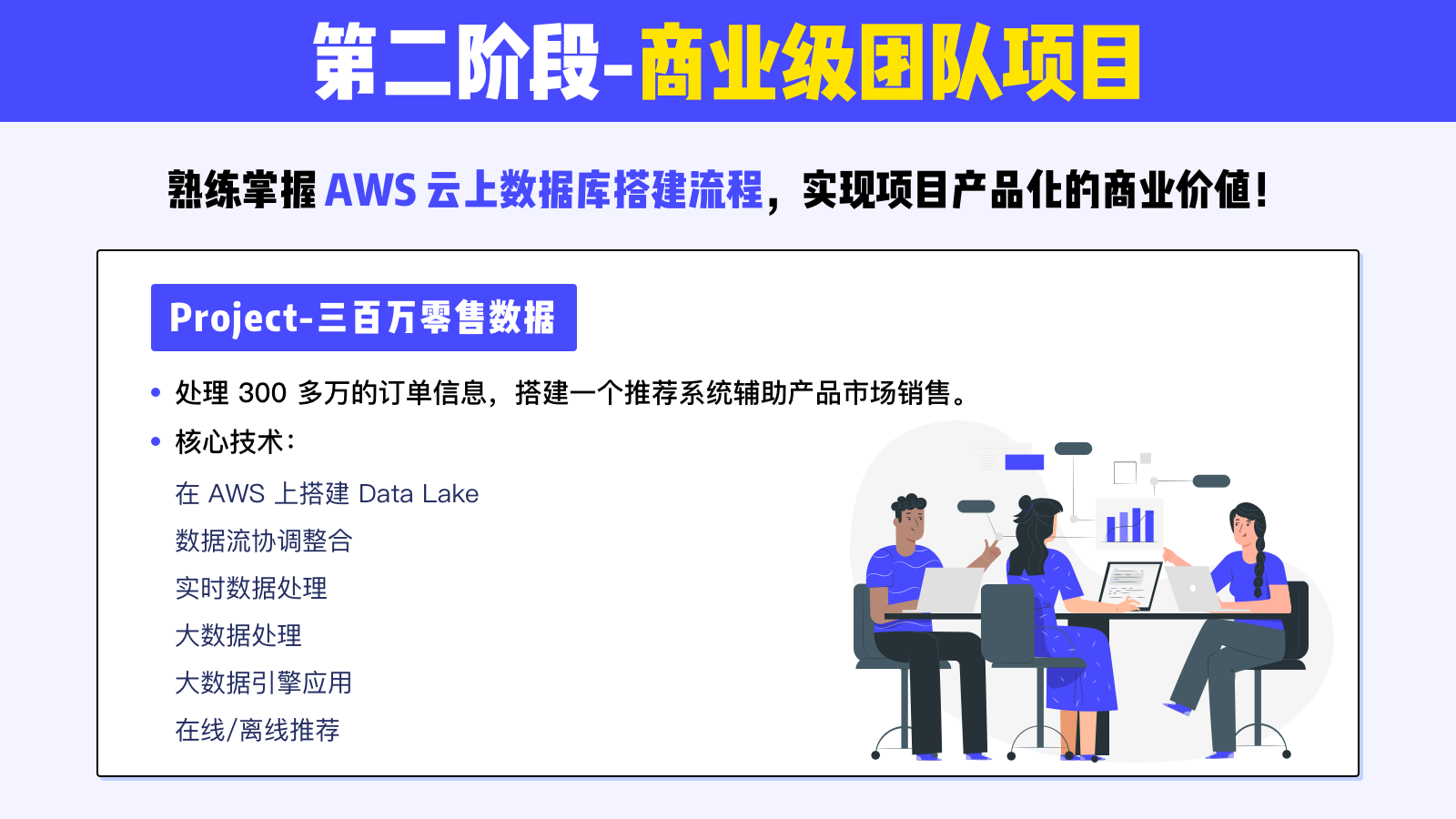
第二阶段:商业级团队项目
有丰富实战经验的技术型人才在市场中更有竞争力。在课程内,学生会完成一个团队大项目,更加熟练掌握 AWS 云上数据库搭建流程,实现项目产品化的商业价值。
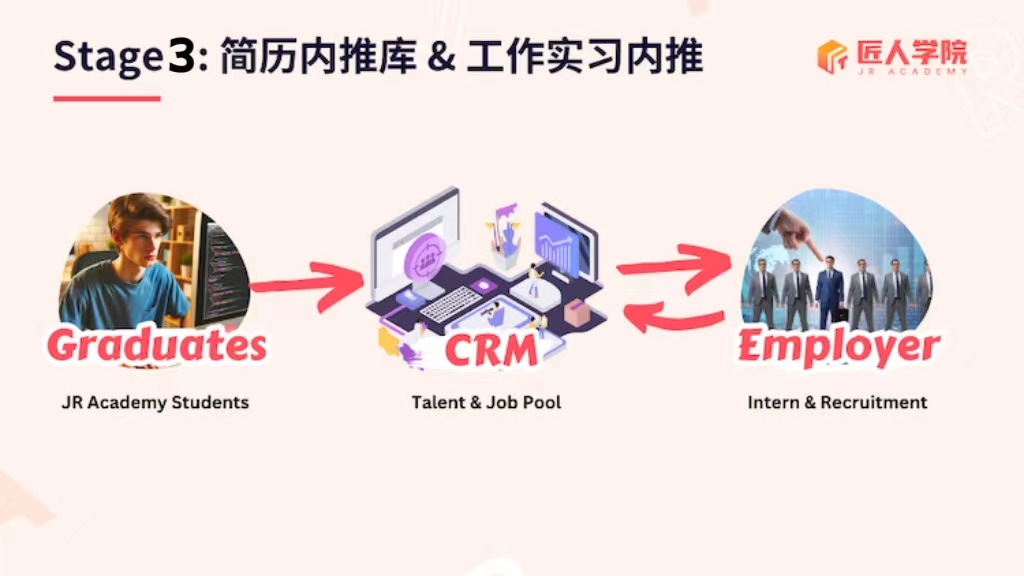
第三阶段:简历内推机会
匠人毕业学员的简历,有权优先录入简历内推库。依托匠人长久积累的的企业伙伴和毕业校友、导师的长久合作,这些简历会被优先推荐和匹配合适的岗位,有效缩短求职路径。
第四阶段:IT Career Coaching Self-Pace Learning
80+ Career Coaching课程,从职业规划,简历,面试,谈薪水等多方面提升。
职业规划:澳洲IT行业全景、个性化职业规划、个人品牌打造
找到第一份工作:CV&LinkedIn、面试技巧与策略、行为面试技巧、技术面策略
升职跳槽加薪:System Design面试、薪酬谈判的艺术、升职加薪策略、突破收入天花满
为什么要学习数据工程全栈项目班?
由于目前大学并没有提供系统的培训,一般行业内的数据工程师都是由社会培训,并且企业更偏向于拥有丰富项目经验的数据工程师,就业门槛相对于数据分析师来说更高一些。而我们课程的导师都是来自各个行业,且经验丰富,通过他们的指导,可以快速获取 Offer 直通车的门票。
项目经验丰富,由团队精神的分析师是面试官的首选。匠人多角色团队项目的设计模式更贴合澳洲的真实职场环境,让学生提前熟悉数据工程师的日常工作流程,增加个人竞争力。这是自学没办法媲美的。而且随着匠人培训 5.0 模式的升级,训练营的内容得到越来越多的企业认可。目前已经与德勤,Servian 等公司建立合作关系,能给优秀学员争取更多的内推机会。
数据工程全栈项目班亮点
1.一线大厂明星导师精心打造,进行直播面对面授课
课程导师均来自澳洲一线大厂,具备多年数据岗位从业经验,传授当下招聘市场需要的技术知识以及真实有效的行业经验
2.串联数据工程知识点,有效进行系统学习
数据工程的核心是如何把不同的工具,和技能串联在一起,不同的接口如何链接,这就需要一个系统化更高维度的学习。课程中涵盖了目前市面上对数据工程师求职所需的所有技能点。除了日常的直播授课外,还会有不定期的 Tutorial 作为指导,帮助你加速理解知识点。课程中包括了如下的知识体系和内容:
数据库基础操作
帮助学生巩固基础知识,主要知识点包括数据库管理系统(DBMS), 数据库查询语言 SQL 以及关系型数据库等。
数据存储
了解大数据的两大存储方式:数据仓库(Data Warehouse)和数据湖(Data Lake)。了解数据探索的几种方法。
大数据
带你了解大数据常用数据结构,并结合谷歌云服务 GCP 学习云端处理大数据的基本操作和可用服务。
数据建模&机器学习
掌握回归、支持向量机 SVM、决策树等几种机器学习算法,了解真实工作中分析数据的流程,从需求分析、数据建模到获取结果。
Python 数据分析
学习使用 Python 进行数据分析,学习 Python 相关模块。
数据可视化
学习利用 Tableau 可视化数据结果,并通过十多个不同案例掌握数据可视化的具体操作。
AWS 部分
学习使用亚马逊云服务 AWS 的服务和功能,上手云端搭建数据工程,最实际、最有竞争力的行业必备技能

3.简历内推库
让学员“不仅仅是获得实习,更成为工作 offer 收割机”
简历内推库是一个特设的、专为我们的学员打造的数字化简历存储平台。在这里,每位学员的简历都经过专业导师的审核与优化,确保其准确、专业且符合行业标准。
4.优秀同学内推机会
匠人受到许多企业的认可,我们会根据学生项目完成质量及项目 Tutor 对学生的评价,对项目中表现优秀的同学进行优先内推。
数据工程全栈班和别的课程对比

学员真实 Offer 展示
自数据工程全栈班开班以来,有超 200+ 同学进入澳洲各大公司如 afterpay,Mecca 和 Thoughtworks 等工作。
课程适合人群
本课程专为 IT/CS/DS/IS 专业的毕业生和在校生设计,帮助学员跃升为掌握职场技能的数据工程师和数据科学家。
你需要掌握:
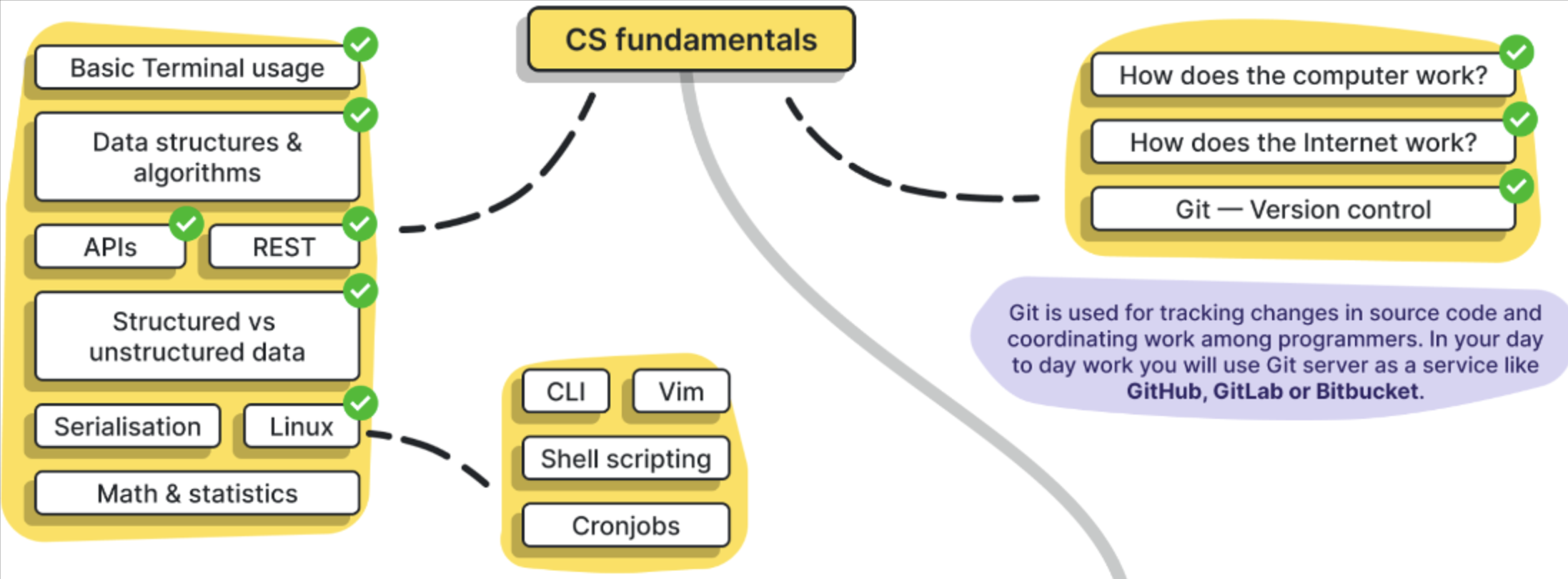
课程不适合
完全不了解 Python 的基础知识
没有 SQL 基础知识
学员权益大盘点,属于匠人学员的专属礼遇
概念界定
匠人学员:凡报名过匠人数据工程全栈项目班的学员
新学员:报名数据工程全栈项目班后,第一次参与课程期间,统称为新学员
老学员:报名数据工程全栈项目班后,第一次参与的课程结课后,统称为老学员(这里主要指 enroll 课程期间内)
⚠️以下权益仅限购买课程本人使用,禁止售卖和转让,一经发现封号处理

随到随学
不确定?先从视频课开始
相同方向的视频课程,按自己的节奏学习,价格更友好


视频课学员报名训练营可享差价抵扣
分享此页面
将 机器学习&数据工程全栈项目班 分享给朋友
LIVE CLASS
我们如何线上上课的
- 灵活的学习交流时间:随时随地进入课堂
- 沉浸式学习环境:通过虚拟空间创建了一个高度互动和沉浸式的学习环境。学生可以在虚拟教室、实验室和会议室中进行交流和合作,增强了参与感和实际的课堂体验。
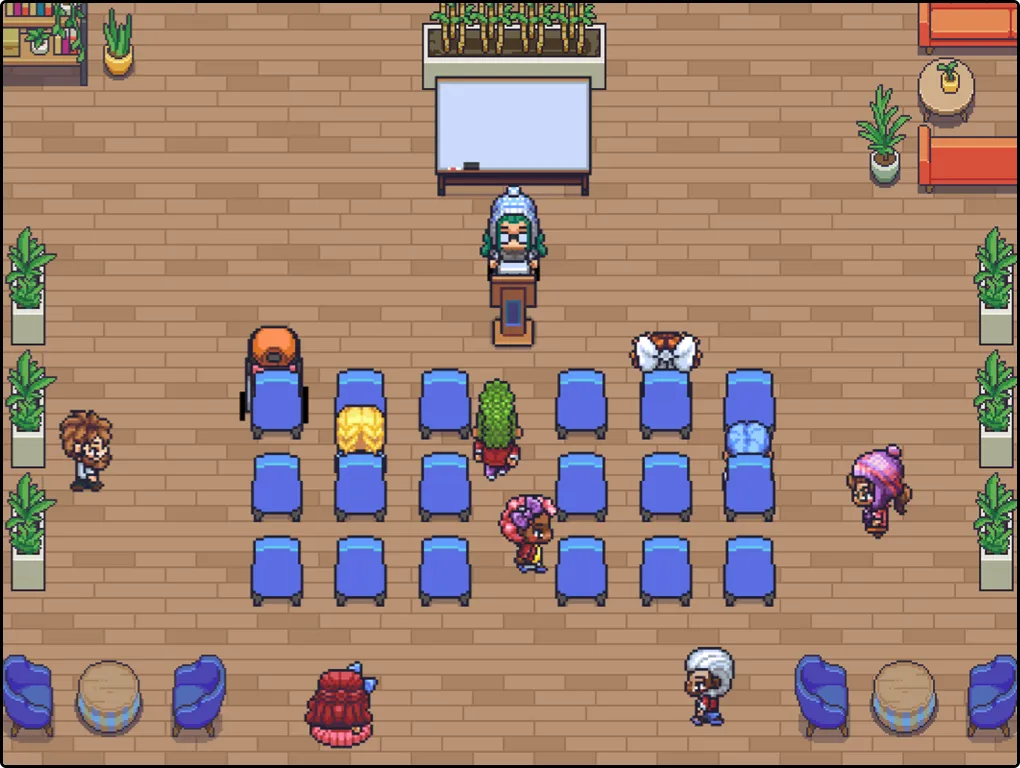
SOCIAL
线上学习减少孤单感
- 减少学习孤单感:看看还有谁和你在学习,找到志同道合的学习伙伴,共同进步。
- 提升社交能力:虚拟环境中,学生可以自由结交新朋友,进行社交互动。这有助于提升学生的社交能力和团队协作精神,特别是对内向或害羞的学生来说,虚拟环境提供了一个更舒适的交流平台。
PROJECT
我们如何讨论项目?如何团队做项目
- 快速建立紧密的团队协作氛围:更高效真实的进行讨论
- 即时反馈和支持:教师和助教实时观察学生的学习情况,提供即时的反馈和支持。这种即时反馈机制有助于及时解决学生的问题,增强学习效果。
地址
Level 10b, 144 Edward Street, Brisbane CBD(Headquarter)Level 2, 171 La Trobe St, Melbourne VIC 3000四川省成都市武侯区桂溪街道天府大道中段500号D5东方希望天祥广场B座45A13号Business Hub, 155 Waymouth St, Adelaide SA 5000Disclaimer
JR Academy acknowledges Traditional Owners of Country throughout Australia and recognises the continuing connection to lands, waters and communities. We pay our respect to Aboriginal and Torres Strait Islander cultures; and to Elders past and present. Aboriginal and Torres Strait Islander peoples should be aware that this website may contain images or names of people who have since passed away.
匠人学院网站上的所有内容,包括课程材料、徽标和匠人学院网站上提供的信息,均受澳大利亚政府知识产权法的保护。严禁未经授权使用、销售、分发、复制或修改。违规行为可能会导致法律诉讼。通过访问我们的网站,您同意尊重我们的知识产权。JR Academy Pty Ltd 保留所有权利,包括专利、商标和版权。任何侵权行为都将受到法律追究。查看用户协议
© 2017-2026 JR Academy Pty Ltd. All rights reserved.
ABN 26621887572