Data Scientist被Harvard Business Review 评为21世纪最性感的职业之一,麦肯锡预测全球将有超过1.5个Million的空缺职位。在人工智能和金融科技大肆兴起之后,Data Science作为一切的根基,求职者们更变成了最炽手可热、千金难求的人才!
今天数据行业只能用一个字形容: 火
无论哪个行业,应该会每年都被数据时代,大数据,数据分析,商业智能,听过这些名词,在人工智能时代到来的大背景下,许许多多人开始恐慌,不知道什么时候会被替代,有什么时候能够进入到该行业,自己不会被未来取代。

数据科学已经进入到了各个领域 ,由于技术的支撑,Data Science还有很大的市场需求,根据功能性来看,Data Science在诸多领域都有应用,它帮助了企业改变传统的拍脑子做决定的决策方法,现在越来越多公司都采取数据驱动的方式来做商业决策。
Data Scientist被Harvard Business Review 评为21世纪最性感的职业之一,麦肯锡预测全球将有超过1.5个Million的空缺职位。在人工智能和金融科技大肆兴起之后,Data Science作为一切的根基,
DS的问题
我们可以把Data Science中的问题分为几大类:
- What’s the statistics。比如一组数据的平均数、最大值、最小值是多少,数据分布是怎样的,这类问题是很基础的Data Science问题。
- Is A better than B?这个非常常见,比如很多网站有自己的UI Design,他们有时候就要问,网站这个位置的颜色是用蓝色好还是绿色好呢,这就是Is A better than B问题。
- Is this A or B?例如,Facebook上每天都有大量新闻产生,那么我们如何智能地判断一个新闻是真的还是假的呢,这就是一个Is this A or B问题。
- How much?想研究一个变量,但是不知道这个变量应该被预测为多少,那么就需要问How much这个问题。
- 大量的数据中可能存在一个Pattern,想知道这个Pattern是什么我们就要问How is data organized
- What’s future?已知现有数据和历史数据,怎样预测未来的数据?
- Is this weird?已知一组数据,其中有几个数据与其他的数据不一样,那么这些数据不一样到什么程度才会被认为是weird的?
- What will users like?预测用户喜欢什么。
以下来自Albert导师
分析数据行业的思路和切入点是从一个数据项目的software development lifecycle。也就是经常能看见的缩写SDLC进行分析。一般的一个完整的Data project,不管大小或者复杂程度都要经过这么几个步骤,第一是Data Capture,有的也叫做data ingestion也就是从不同的数据源把数据获取并导入到系统中。常见的数据原有传统关系型数据库,屏文件,流数据,机器日志,API获取数据等等。第二部是data store and process。也就是。数据清洗加工转化和存储的步骤。有个更好的术语去形容他就是ETL(extract transform and load)。当然还有一个时髦的词可以形容这个步骤就是data wrangling,当数据经过ETL。按数据模型整齐的加载到数据库中或者是其他数据存储中。
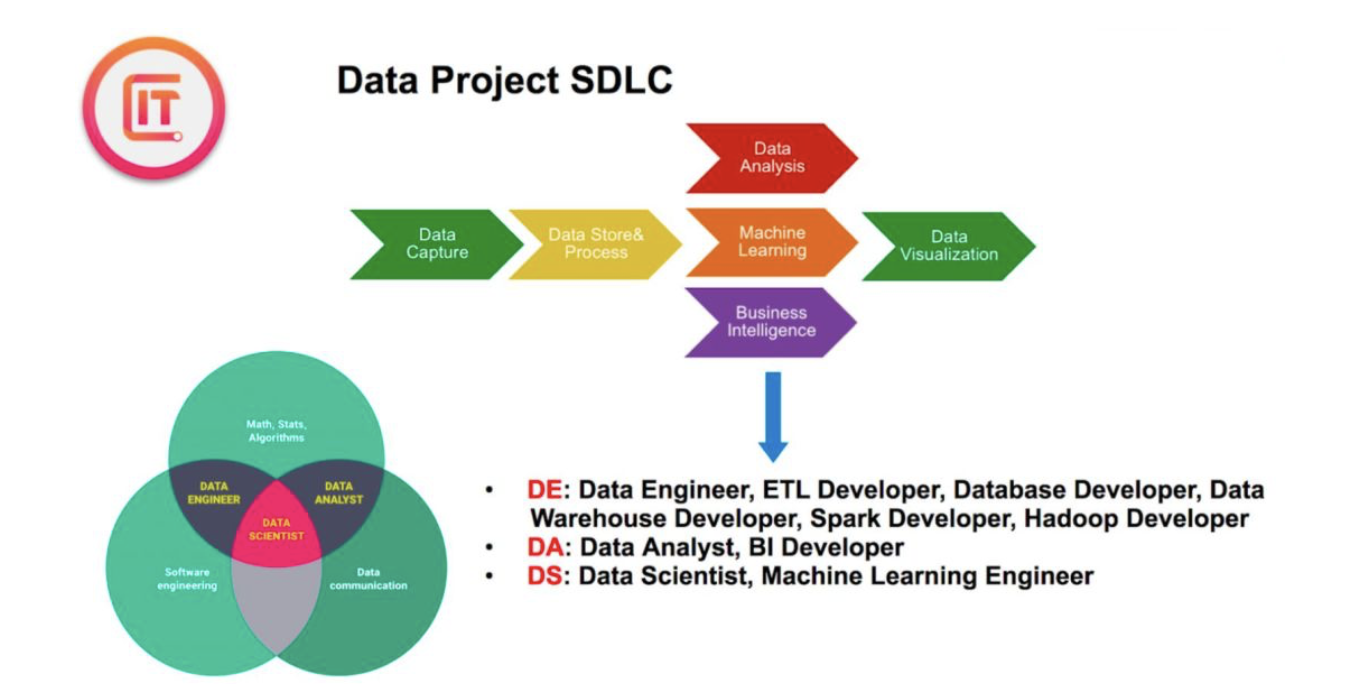
那么这些数据就可以用来回答商业问题,作出预测,实现商业价值等等。所以第三步我并排的 画了三个方向,这些数据可以做Data analysis/machine learning/business intelligence。第四 步,data visualization是第三部的一个结果不管用数据做何种分析。80%的情况是需要有数据 的图形展示以用来证明假设推断。并tell story, 让客户用户更好的理解和使用数据。
现在对数据项目的SDLC有了大致的了解。那么数据相关三大职业DE/DA/DS就在这个流程中诞生了,DE(Data Engineering)的主要工作发生在前两步,使用编程或者工具对数据
进行获取和转化的工种。根据使用的技术和工具不同,有很多称谓。DA(data analysis)是在一 个business context下,对于数据进行分析,以回答商业问题,满足商业需求的工作。
最后DS(data scientist)是DA的加强升级版本主要武器是machine learning,用来做predictive analysis而不是简单的descriptive analysis。DA和ds最关键的区别在于ds绝大多数情况下都是 用feature engineering/machine learning进行预测分析和解决商业问题的。
需要指出的是de/da/ds这三种公种在现实情况中无法每次都百分之百严格的区分。其实三种工 种的技能都有很多overlap,比如etl这个技能。DA和ds同样需要掌握,但是没有第一那么深 入。de可以说是专门专门处理各种etl场景的职位。只要是澳洲各个公司对这个职位定义都不 完全相同,比如澳洲很多公司。招聘ds都希望ds有de的技能可以从data capture做起,再比如 有的公司对Da和ds有着严重的混淆。在有的公司title虽然是datascientist,但是这个职位甚至 很少做算法模型。
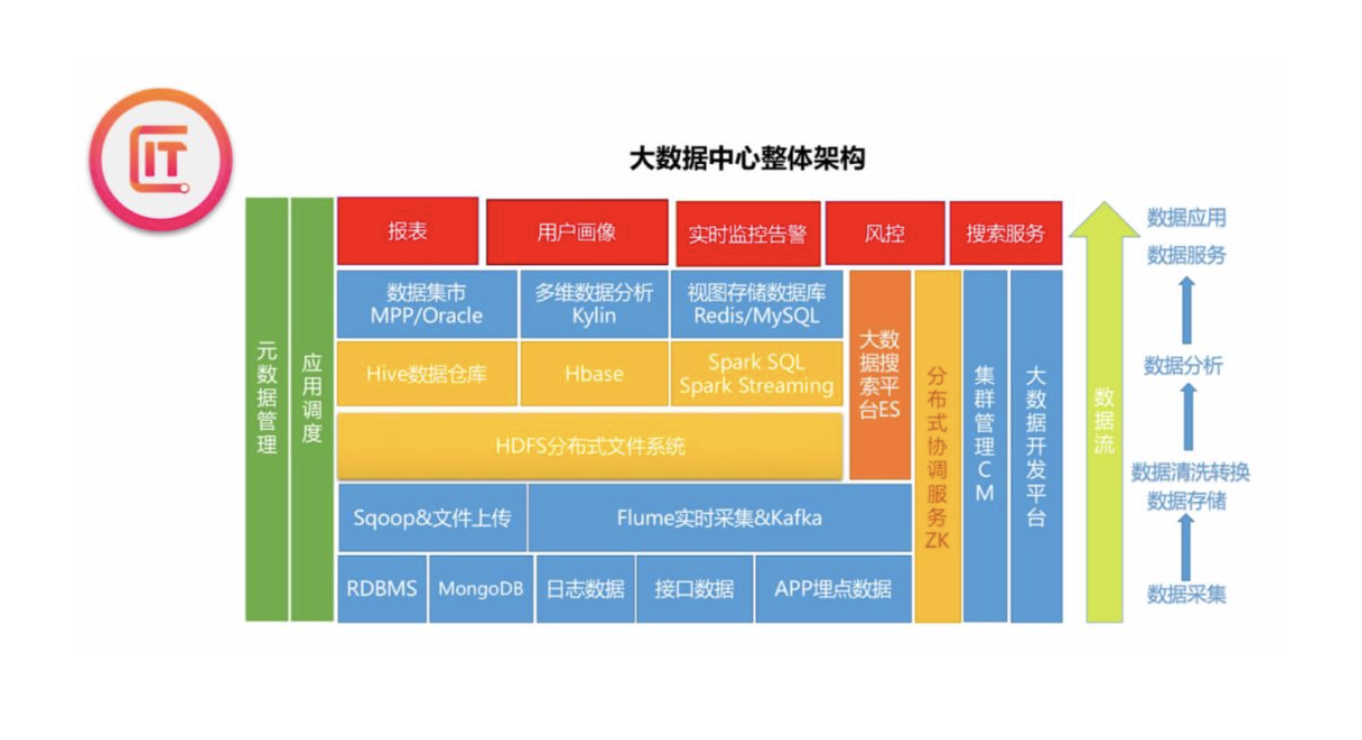
接着给大家再看一个数据中心的架构图,要构建这么一个数据中心基本也是遵循我前面讲的四 个步骤。对于不同模块的工作产生了不同的岗位data engineer会负责所有数据的获取。转化 和存储的工作而DS/DA。会在红色模块报表用户画像,风控中工作。
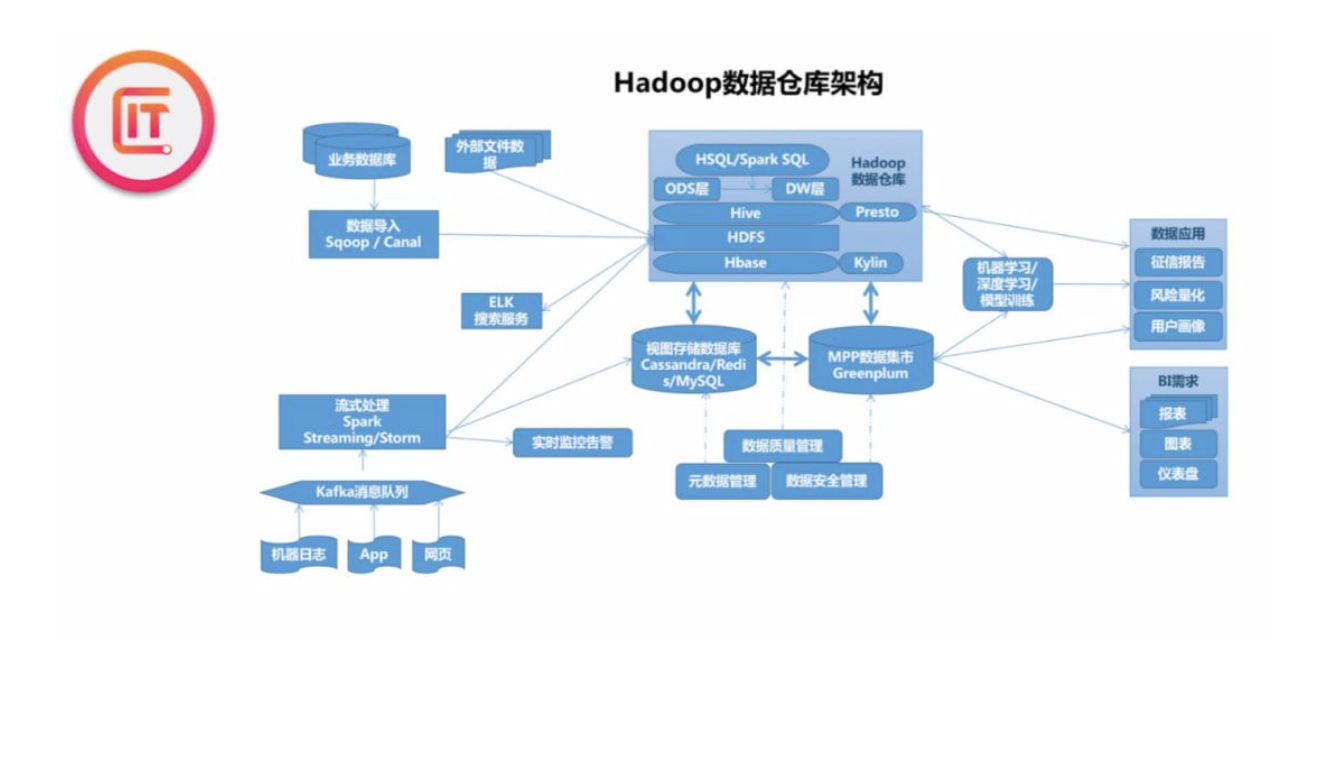
下面这张图是从数据流的角度对前面那张图的进一步阐释,可以看到同样的。DE会负责所有 数据的获取转化和存储的工作。而DA、DS会在数据的应用和商业需求方面进行工作。
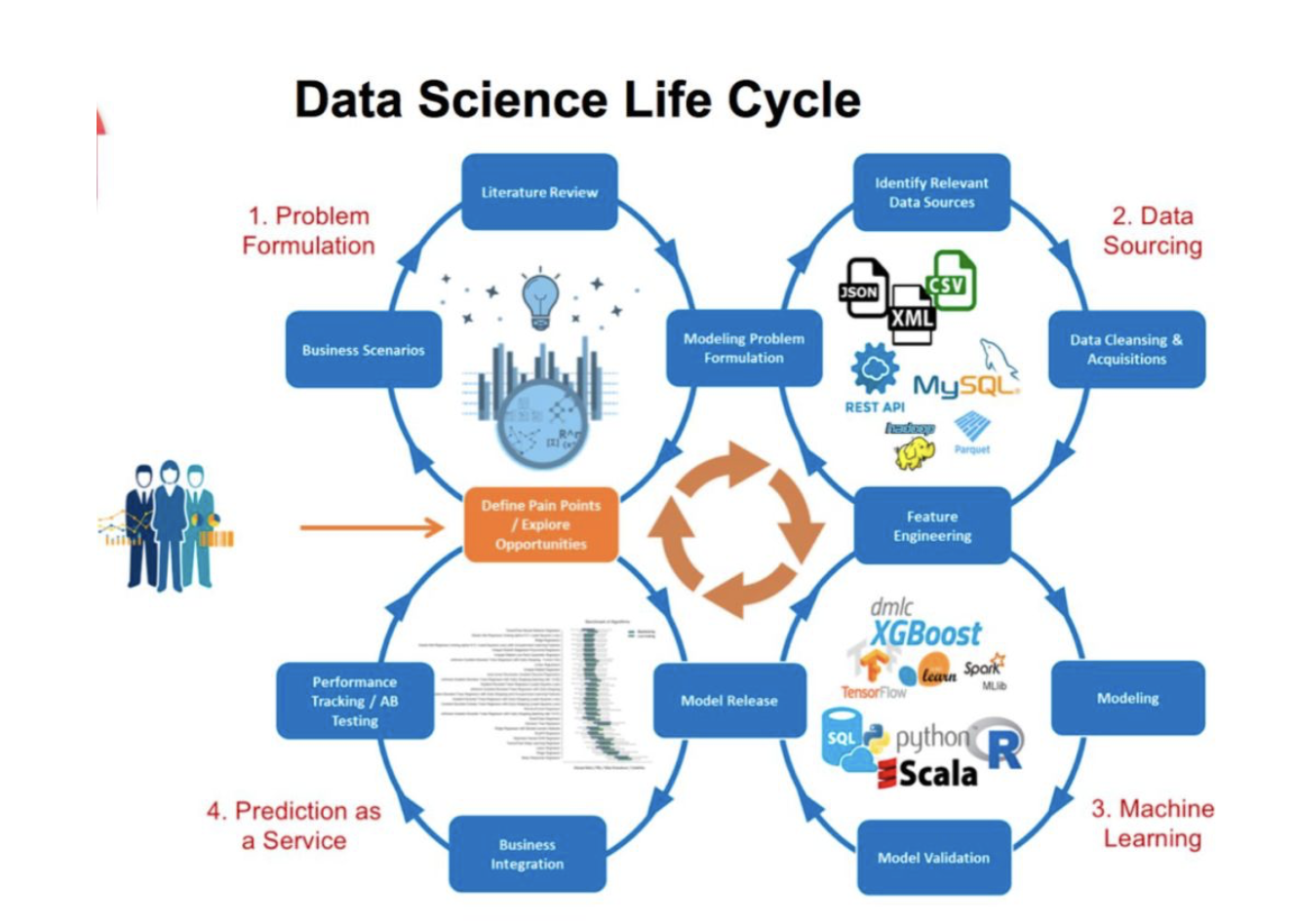
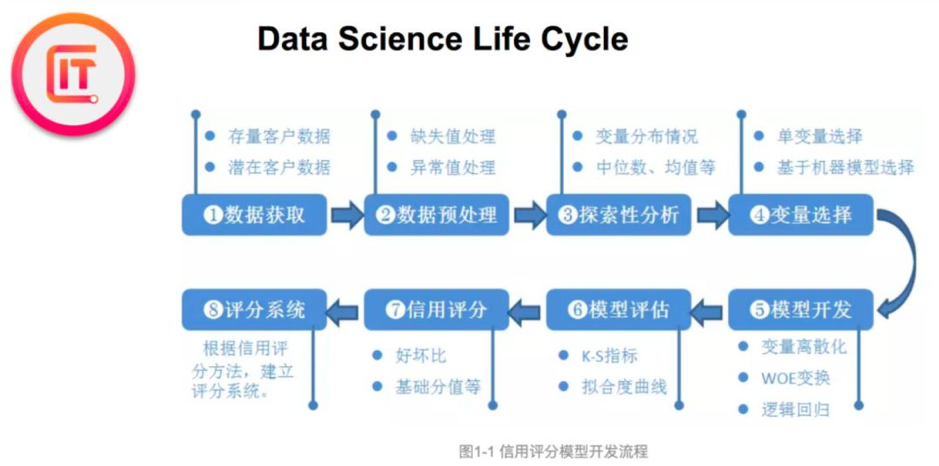
我们前面讲了一个完整的数据项目地流程。但是如果只看DS这一部分。其实他也有自己的一 个流程基本是所谓的四步骤,后面许光老师也会给我们具体讲一个数据科学的项目。好第一步 是问题表述其实就是what's your problem,大多数data scientist的工作就是为了解决在一个特 定商业场景下的商业问题。从而做出正确的决策。举例来说银行贷款给个人或者小微企业那么 第一个问题是能不能带给这个人或者小微企业呢,第二个问题是到底可以带多少呢。
那么第二个步骤是数据搜寻。有哪些数据是可以用的,这些数据的源头是什么,能通过什么方 式获取。需要data engineer帮助获取数据或者build data pipeline么。这些数据有隐私和安全 限制吗,这些都是第二个步骤,数据搜寻许所需要考虑的。
第三部分就是我们真正分析建模的步骤。其实在这个步骤呢,我们又可以细分为数据预处理、 探索性分析、feature engineering、建模、模型评估、模型发布这几步。第四个步骤prediction as a service。什么意思呢,就是真正把我们第三部分的模型deploy到生产中形成形成一种产品或者服务。并且不断做performance tracking and 提高和进化模型。据我了解澳洲只有为数 不多的几家公司做到了,第四个步骤。
数据科学全栈班开班了
课程名:数据科学项目全栈班
课程时长:90个小时+Career Coaching
授课地点:墨尔本+面授+远程
你为什么想上这个课程:
从理论到实践,在澳洲找到你梦寐以求的数据科学相关工作
适合人群:
想从事数据科学方向工作的有一定基础的IT学生
想获得宝贵项目经验并转方向的在职人员
通过课程你可以获得的重要求职技术点:
- Apache Spark/Kafka进行大数据处理
- Tensflow
- 机器学习算法原理/调参/解决真实问题
- 时序数据可视化/预测
- 时空数据可视化/预测
- 如何正确使用Python/R 进行数据处理
- 回归分析/聚类方法/分类算法
通过课程你可以获得的
由业界资深导师定制的四大项目
- 时序数据-比特币价格预测
- 基于Apache Spark/Kafka的大数据分析
- 时空数据聚类和预测-墨尔本停车费罚款优化
- Kaggle真实竞赛指导
定制化的Career Coaching
IT匠人社群Networking与内推资源
课程价格:
线下:$5,500 早鸟价:$4,800 (9月28截止)
线上:$4,500 早鸟价 $3, 800(9月28截止)
开课时间:10月20日 星期六