Polars:让你的数据处理快到离谱
你第一次用 Polars 大概是这样的:Pandas 跑了 3 分钟的脚本,你抱着试试看的心态换成 Polars,8 秒跑完。你盯着终端看了半天,以为哪里写错了,结果一检查——数据完全正确。
这不是夸张,我在一个 2GB 的 CSV 清洗任务上亲身经历过。当时 Pandas 的 read_csv + groupby + merge 一套下来要 4 分钟,Polars 的 lazy mode 同样逻辑 11 秒结束。那一刻我就知道,这玩意不是玩具。
#先说结论:你到底该不该换 Polars
我直接给结论,省得你翻到最后:
- 数据量 < 100MB:别折腾,Pandas 够用,生态也更成熟
- 数据量 100MB - 1GB:可以试试,尤其你已经受不了 Pandas 的速度
- 数据量 > 1GB:强烈建议换,Polars 的优势是碾压级的
- 数据量 > 10GB:Polars + scan_parquet 的 lazy mode 是你为数不多的选择之一(另一个是 DuckDB)
一句话:如果你现在的 Pandas 脚本跑得你想去泡杯咖啡,那就是该换的时候了。
#核心区别:不只是快,是思路完全不一样
先看对比表:
| 对比项 | Polars | Pandas |
|---|---|---|
| 底层语言 | Rust | C/Cython |
| 执行模式 | 惰性求值 + 自动并行 | 即时求值、单线程 |
| 内存格式 | Apache Arrow 列式存储 | NumPy 行式 |
| API 风格 | 链式表达式、不可变 | 就地修改、索引驱动 |
| 大数据表现 | 可处理超出内存的数据 | 全部塞进内存,塞不下就炸 |
| 多线程 | 自动用满所有 CPU 核心 | 默认单线程,手动并行很痛苦 |
| Index | 没有 Index 这个概念 | 到处都是 Index,经常搞混 |

但光看表格感受不到本质区别,我用几个类比说清楚。说到这个我想起来,我第一次接触 Polars 其实是在一个同事的 PR review 里看到的,当时还以为是个小众玩具库,结果一试直接真香。
#惰性求值 = 点菜制 vs 自助餐
Pandas 是自助餐模式:你每写一行代码,它立刻执行。df.filter() 马上算,df.groupby() 也马上算。哪怕下一步你要把这个中间结果扔掉,它也老老实实算完了。
Polars 的 lazy mode 是点菜制:你一口气写完所有操作,它先不动,等你说 .collect() 的时候,才把所有操作一起优化、一起执行。就像你在餐厅点了 5 道菜,厨房会把能一起炒的一起炒,而不是做完一道上一道。
python# Pandas:每一步都立刻执行,中间产生大量临时 DataFrame df = pd.read_csv("huge.csv") # 全部读进内存 df = df[df["age"] > 30] # 马上过滤,产生新 DataFrame df = df.groupby("city").agg({"salary": "mean"}) # 马上聚合 # Polars lazy:先攒着,最后一起算 result = ( pl.scan_csv("huge.csv") # 不读,只记住"要读这个文件" .filter(pl.col("age") > 30) # 不算,只记住"要过滤" .group_by("city") # 不算 .agg(pl.col("salary").mean()) # 不算 .collect() # 这时候才一口气全算完,自动优化执行计划 )
这个差距在简单操作上感觉不大,但一旦链路长了、数据大了,Polars 的查询优化器能帮你省掉大量不必要的计算。
#并行执行 = 高铁 vs 绿皮火车
Pandas 本质上是单线程的。你的电脑有 8 个核,Pandas 只用 1 个,剩下 7 个在看戏。
Polars 用 Rust 的 Rayon 库自动把任务分配到所有 CPU 核心。你不用写任何多线程代码,它自己搞定。这就像高铁和绿皮火车的区别——不是绿皮火车司机技术差,而是轨道和车本身就不在一个级别。
#没有 Index = 少掉 80% 的坑
说实话,Pandas 的 Index 是我见过最容易让新手翻车的设计。reset_index()、set_index()、merge 之后 Index 乱掉、MultiIndex 搞不清层级……这些坑你踩过几个?
Polars 直接砍掉了 Index。行就是行,列就是列,没有隐藏的 Index 在背后搞事情。最省力的办法就是不给你犯错的机会。
#迁移指南:Pandas → Polars 对照表
已经会 Pandas 的人,看这个表就能快速上手:
#读写数据
python# Pandas # Polars pd.read_csv("f.csv") pl.read_csv("f.csv") # eager pl.scan_csv("f.csv") # lazy(推荐) pd.read_parquet("f.parquet") pl.read_parquet("f.parquet") pl.scan_parquet("f.parquet") # lazy df.to_csv("out.csv") df.write_csv("out.csv") df.to_parquet("out.parquet") df.write_parquet("out.parquet")
#选列和过滤
python# Pandas # Polars df["col"] df["col"] 或 df.select("col") df[["a", "b"]] df.select("a", "b") df[df["age"] > 30] df.filter(pl.col("age") > 30) df.loc[0:5] df.head(5) 或 df.slice(0, 5) df.query("age > 30 & city == 'SYD'") df.filter((pl.col("age") > 30) & (pl.col("city") == "SYD"))
#聚合和分组
python# Pandas # Polars df.groupby("city")["sal"].mean() df.group_by("city").agg(pl.col("sal").mean()) df.groupby("city").agg({ df.group_by("city").agg([ "sal": "mean", pl.col("sal").mean(), "age": ["min", "max"] pl.col("age").min(), }) pl.col("age").max(), ])
#新增列和修改
python# Pandas # Polars df["new"] = df["a"] + df["b"] df = df.with_columns((pl.col("a") + pl.col("b")).alias("new")) df["cat"] = df["x"].apply(func) df = df.with_columns(pl.col("x").map_elements(func)) df.rename(columns={"a": "b"}) df.rename({"a": "b"}) df.drop(columns=["x"]) df.drop("x")
#合并和连接
python# Pandas # Polars pd.merge(df1, df2, on="id") df1.join(df2, on="id") pd.concat([df1, df2]) pl.concat([df1, df2])
#最容易翻车的地方
这几个坑我自己或者身边人都踩过,提前告诉你:
#1. 忘了 collect(),拿到的是 LazyFrame 不是 DataFrame
pythonresult = pl.scan_csv("data.csv").filter(pl.col("age") > 30) print(result) # 输出的是执行计划,不是数据! # 你得加 .collect() print(result.collect())
新手最常见的困惑就是"为什么打印出来不是数据"。记住:scan_ 开头的返回 LazyFrame,必须 .collect() 才能拿到真正的 DataFrame。
#2. 习惯性写 apply / map,性能直接崩
这个坑我见过不止一次了。有个真实案例:之前组里一个实习生写了个数据清洗脚本,用 Polars 跑反而比 Pandas 还慢,大家都懵了。最后一看代码,满屏的 map_elements(lambda ...),等于把 Polars 的 Rust 引擎完全绕过去了,全程在跑 Python 解释器。改成原生表达式之后,速度直接快了 40 多倍。
python# ❌ 这样写 Polars 会退化成跟 Pandas 一样慢 df = df.with_columns( pl.col("name").map_elements(lambda x: x.upper()) ) # ✅ 用 Polars 原生表达式,快几十倍 df = df.with_columns( pl.col("name").str.to_uppercase() )
能用内置表达式的就别用 lambda,这是 Polars 性能的第一铁律。顺便提一嘴,Polars 的表达式 API 覆盖面其实非常广,字符串、时间、数学运算基本都有原生支持,真正需要写 lambda 的场景没你想的那么多。
#3. 字符串比较用错了
python# ❌ Pandas 思维:直接比较 df.filter(pl.col("status") == "active") # 这个没问题 # ❌ 但 contains 不一样 df.filter(pl.col("name").str.contains("张")) # ✅ 注意是 .str.contains()
Polars 的字符串操作都在 .str 命名空间下,跟 Pandas 的 .str 类似但不完全一样。
#4. 列名重复时 join 会报错
join 的时候同名列记得加 suffix:
pythondf1.join(df2, on="id", suffix="_right")
#5. 不支持就地修改
Pandas 里你可以 df["col"] = xxx,Polars 里 DataFrame 是不可变的(immutable)。所有修改都返回新的 DataFrame:
python# Pandas 思维(Polars 里不行) df["new_col"] = values # Polars 方式 df = df.with_columns(pl.lit(values).alias("new_col"))
#版本注意事项
Polars 更新非常快,API 经常有 breaking changes。几个建议:
- 锁定版本:
requirements.txt里写死版本号,比如polars==1.27.0,不要用>= - 关注 changelog:大版本升级前看一眼 GitHub Releases↗,重点看 Breaking Changes 部分
- 0.x → 1.0 的迁移:如果你还在用 0.x 版本,升级到 1.0 有不少 API 变化,比如
groupby改成了group_by,apply改成了map_elements - Python 版本:建议 Python 3.9+,Polars 已经不支持 3.8
#适不适合你:Checklist
在决定之前,过一遍这个清单:
适合用 Polars 的情况:
- 你的数据处理脚本跑得慢,成为了工作瓶颈
- 你愿意花 1-2 天学新 API(跟 Pandas 像但不完全一样)
- 你主要做 ETL、数据清洗、聚合分析
- 你的数据格式是 CSV、Parquet、JSON
- 你不需要大量用
.plot()画图(Polars 本身没有画图功能)
暂时不适合的情况:
- 你的项目深度依赖 scikit-learn、statsmodels 等只接受 Pandas 的库
- 团队里只有你一个人会 Polars,其他人都用 Pandas
- 数据量很小,当前性能完全够用
- 你需要大量交互式探索(Jupyter 里 Pandas 的体验目前还是更好)
一个折中方案:核心计算逻辑用 Polars,最后转成 Pandas 喂给其他库:
python# Polars 处理完,转 Pandas 给 sklearn polars_df = pl.scan_parquet("data.parquet").filter(...).group_by(...).agg(...).collect() pandas_df = polars_df.to_pandas() model.fit(pandas_df[features], pandas_df[target])
#性能实测参考
以下是一些典型操作在 1GB CSV 上的大致耗时对比(具体数字取决于机器配置,这里给个数量级的感觉):
| 操作 | Pandas | Polars (eager) | Polars (lazy) |
|---|---|---|---|
| 读取 CSV | ~15s | ~3s | ~2s (scan) |
| 过滤行 | ~2s | ~0.3s | ~0.1s |
| GroupBy 聚合 | ~5s | ~0.8s | ~0.5s |
| Join 两表 | ~8s | ~1.2s | ~0.8s |
| 写 Parquet | ~3s | ~1s | ~1s |
注意:lazy mode 的时间包含了 .collect() 的时间。Polars 在 Parquet 格式上优势更大,因为 Arrow 和 Parquet 天生兼容,不需要格式转换。
下面这张是 Polars 官方的 TPC-H 基准测试结果(Scale Factor 10),可以直观看到各个查询上的耗时对比:
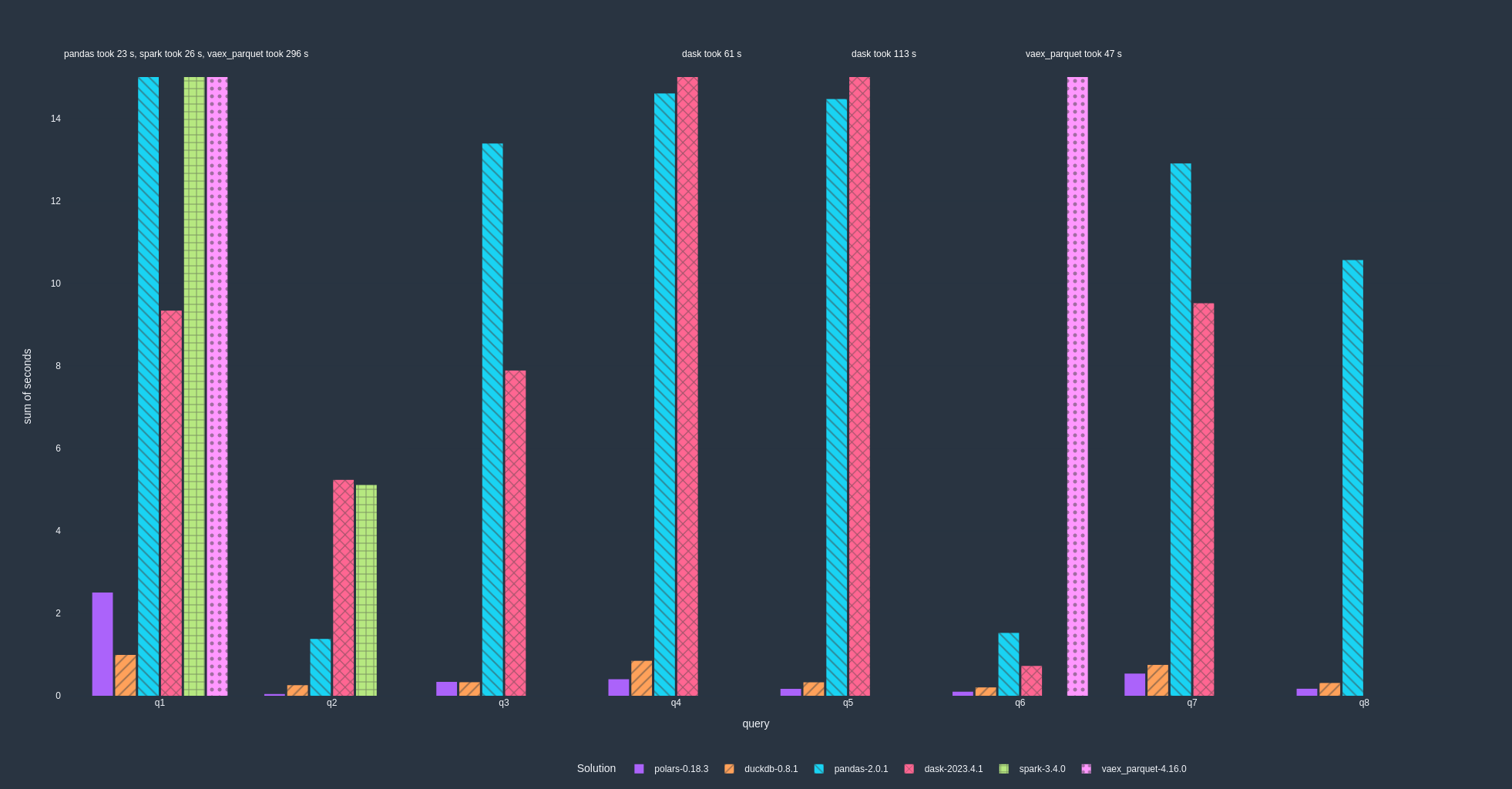
#跟 DuckDB 怎么选
这个问题被问得很多。简单说:
- Polars:Python DataFrame 库,API 是 Python 风格的链式调用,适合写数据处理 pipeline
- DuckDB:嵌入式数据库,API 是 SQL,适合喜欢写 SQL 的人
两者性能差不多,都很快。选哪个主要看你更喜欢写 Python 表达式还是 SQL。也可以一起用,DuckDB 能直接查询 Polars DataFrame。
#相关资源
官方:
- Polars 官网:https://pola.rs↗
- Polars 文档:https://docs.pola.rs↗
- Polars GitHub:https://github.com/pola-rs/polars↗
- Polars 速查表:https://docs.pola.rs/user-guide/↗
相关 Wiki:
- Pandas Wiki — 如果你还没学 Pandas,建议先学 Pandas 再来看 Polars
- DuckDB Wiki — 另一个高性能数据处理方案,用 SQL 的方式
- Apache Arrow Wiki — Polars 底层的内存格式
推荐学习路径:
- 先跑通官方的 Getting Started,感受一下速度差异
- 把一个现有的 Pandas 脚本迁移过来,对照上面的对照表改
- 重点学 Expression API,这是 Polars 最强大的部分
- 理解 lazy vs eager 的区别,日常优先用 lazy mode

