Jupyter Notebook 完全指南
你第一次打开 Jupyter 可能觉得它就是个网页版 Python,但用了一阵你会发现——它更像是草稿纸 + 计算器 + 笔记本三合一。写一行代码、跑一下、看个图、写两句笔记,这个循环在数据分析和 AI 开发里太常见了,而 Jupyter 就是为这个循环设计的。
我当初第一次接触 Jupyter 是在大学做 data science 作业的时候。那会儿教授发了一个 .ipynb 文件过来,我还以为是什么奇怪的格式,折腾了半天才装好环境打开。结果一用就停不下来了——写两行代码马上能看到图表出来,比之前在 PyCharm 里写完整个脚本再跑舒服太多了。后来做毕业项目的时候,我整个数据清洗和可视化流程都是在 Jupyter 里完成的,光 Notebook 文件就攒了二十多个。
十几年过去,数据科学的工具换了一茬又一茬,Jupyter 还是稳稳坐在那里。不是因为它完美,而是因为没有别的东西能完全替代"边想边写边看结果"这个体验。
#Jupyter 生态全景
很多人分不清 Jupyter Notebook、JupyterLab、Colab 到底什么关系。简单说:它们都基于同一个 Notebook 格式(.ipynb),但界面和使用场景不同。
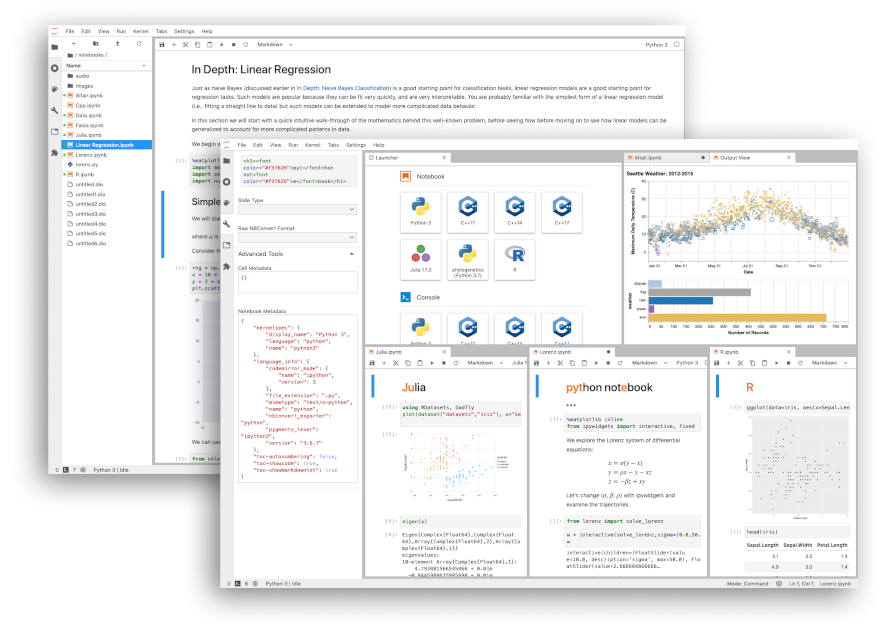
下面是 JupyterLab 的界面,左边文件浏览器、右边多标签编辑区,基本上日常开发都在这个界面里完成:
| 工具 | 定位 | 适合谁 | 免费? |
|---|---|---|---|
| Jupyter Notebook | 经典版,一个标签页一个文件 | 刚入门、做教学演示 | ✅ |
| JupyterLab | 下一代界面,多标签、文件浏览器、Terminal 都有 | 日常开发首选 | ✅ |
| Google Colab | 云端 Notebook,自带免费 GPU | 跑深度学习、不想配环境 | ✅(Pro 付费加速) |
| VS Code Notebooks | 在 VS Code 中原生运行 .ipynb | 已经用 VS Code 的开发者 | ✅ |
| JupyterHub | 多用户部署方案,一台服务器给一个团队用 | 企业/大学 IT 管理员 | ✅ |
| Kaggle Notebooks | Kaggle 平台自带,预装各种数据科学库 | 参加竞赛、快速实验 | ✅ |
话说回来,如果你不想折腾本地环境,Google Colab 是最省心的选择,打开浏览器直接写代码:
选哪个?大多数人的路径是:Colab 入门 → JupyterLab 本地开发 → VS Code 做正经项目。不用一开始就纠结,哪个顺手用哪个。
#核心工作流:Cell 执行逻辑
Jupyter 的基本单位是 Cell(单元格)。每个 Cell 可以是代码、Markdown 文字或者原始文本。你写完一个 Cell,按 Shift + Enter 执行,输出直接显示在下面。
听起来简单,但这里面有个关键概念很多人忽略了:所有 Cell 共享同一个内存空间(Kernel)。
这意味着什么?
python# Cell 1 x = 10 # Cell 2 print(x) # 能拿到 Cell 1 的 x,输出 10 # Cell 3 x = 20 # 如果你回头重新跑 Cell 2,输出变成 20
这个特性是双刃剑——灵活,但也是最容易翻车的地方(后面细说)。
#Cell 的三种状态
[ ]:还没执行过[*]:正在执行(如果卡在这里很久,可能是代码有死循环或者 Kernel 挂了)[3]:已执行,数字代表执行顺序
养成一个习惯:经常看左边的数字。如果数字跳来跳去(比如 1, 5, 3, 8),说明你的执行顺序已经乱了。
#最容易翻车的地方
用 Jupyter 越久,越会遇到这些坑。提前知道能省不少时间。
#1. 执行顺序混乱
这是 Jupyter 被骂得最多的问题,我自己就在这上面栽过大跟头。
有一次做课程作业,我在 Cell 10 定义了一个 clean_data 函数,后来觉得写得不好,删掉了那个 Cell 重写了一版放在 Cell 15。问题是删掉 Cell 10 之后,旧的 clean_data 还留在内存里,代码照样跑得好好的,结果也看着没问题。我就这么交了作业。第二天教授说跑不通,我打开一看——Kernel 重启之后,旧函数没了,Cell 15 的新版本依赖了一个我在 Cell 12 里临时定义的变量,而 Cell 12 其实在 Cell 15 下面。整个执行顺序完全是乱的,我自己跑的时候因为内存里什么都有所以没问题,换个干净的环境就全崩了。
更隐蔽的情况是这样的:你在 Cell 3 写了 df = df.dropna(),跑了一遍,然后又手动跑了一遍——数据被 dropna 了两次,但你可能根本没注意到。或者你在调试的时候不断修改某个 Cell 的逻辑,跑了七八遍,内存里的状态已经和代码文本完全对不上了。
解决办法:写完一段逻辑后,养成习惯用 Kernel → Restart & Run All 从头到尾跑一遍。如果全部通过,说明你的代码是"可复现"的;如果报错,就是有隐藏的依赖顺序问题。我现在基本上每写完一个小模块就会 Restart & Run All 一次,虽然慢一点但省得后面出幺蛾子。
#2. Kernel 死了
跑大数据集的时候 Kernel 直接挂掉是常事,Cell 一直显示 [*],右上角状态变灰。遇到这种情况直接 Kernel → Restart 重启就行,所有变量会清空。大文件记得用 chunksize 分批读,别一口气全加载进内存。
#3. .ipynb 版本控制是噩梦
.ipynb 文件本质是 JSON,里面包含代码、输出、图片(Base64 编码)、元数据。你改一行代码,Git diff 可能显示几百行变化——因为输出也变了。
实用解决方案:
| 方案 | 操作 | 适合场景 |
|---|---|---|
nbstripout | 自动清除输出后再 commit | 个人项目 |
nbdime | 专门给 Notebook 做 diff 和 merge | 团队协作 |
jupytext | 把 .ipynb 同步成 .py 或 .md | 想用纯文本管理 |
| Review Board / Colab | 不走 Git,直接在线协作 | 快速实验 |
个人建议:如果是正经项目,核心逻辑抽到 .py 文件里,Notebook 只做调用和可视化。这样 .py 走正常 Git 流程,Notebook 当一次性的实验记录。
#4. Notebook 越写越长收不住
一个 Notebook 写到 200 个 Cell,自己都找不到之前写的东西在哪。
经验法则:
- 一个 Notebook 聚焦一个任务(数据清洗一个、建模一个、可视化一个)
- 超过 50 个 Cell 就该考虑拆分了
- 用 Markdown Cell 做章节标题,形成清晰的结构
#AI 时代的 Jupyter
2024 年之后,Jupyter 的使用方式发生了很大变化。以前你得自己一行行写 pandas 代码,现在很多人的工作流变成了:
- 把数据描述和需求告诉 ChatGPT 或 Claude
- 拿到生成的代码,粘贴到 Jupyter Cell 里
- 跑一下看结果,不对就调整 prompt 重新生成
这种方式确实快,但有几个要注意的:
- 先理解再粘贴。AI 生成的代码可能用了你不熟悉的库或者有微妙的 bug,盲目跑可能得到错误的结果还不知道
- 分步执行。不要把 AI 给你的 50 行代码一股脑放一个 Cell,拆成几个 Cell 逐步验证
- 检查数据假设。AI 不知道你的数据有没有空值、有没有重复、列名是不是它猜的那个
我个人觉得这种"AI 写代码 + Jupyter 验证"的组合,短期内可能是数据分析最高效的工作流了。纯靠 AI 不靠谱,纯手写又太慢,Jupyter 正好卡在中间那个验证和调试的位置上。
对了还有个事,一些 AI 增强的 Notebook 工具值得关注:
- GitHub Copilot in VS Code Notebooks:直接在 Cell 里自动补全
- Google Colab AI:内置 AI 代码生成功能
- Cursor + Notebook 支持:用 AI 解释和修改整个 Notebook
- Claude Artifacts:可以直接生成带数据可视化的完整代码片段
#实用技巧
#快捷键(JupyterLab / Classic Notebook)
Jupyter 有两种模式:Command 模式(按 Esc 进入,Cell 边框变蓝)和 Edit 模式(按 Enter 进入,Cell 边框变绿)。
| 快捷键 | 模式 | 作用 |
|---|---|---|
Shift + Enter | 通用 | 执行当前 Cell 并跳到下一个 |
Ctrl + Enter | 通用 | 执行当前 Cell,光标不动 |
A | Command | 在上方插入新 Cell |
B | Command | 在下方插入新 Cell |
DD | Command | 删除当前 Cell(按两次 D) |
M | Command | 把 Cell 转成 Markdown |
Y | Command | 把 Cell 转成 Code |
Z | Command | 撤销删除 Cell |
Shift + M | Command | 合并选中的 Cell |
Tab | Edit | 代码补全 |
Shift + Tab | Edit | 查看函数文档 |
#Magic Commands
这是 IPython 特有的功能,在代码前面加 % 或 %%:
python# 计时:看这行代码跑了多久 %timeit sorted(range(1000)) # 整个 Cell 计时 %%time import pandas as pd df = pd.read_csv("data.csv") # 查看当前所有变量 %who %whos # 更详细的版本 # 直接跑 shell 命令 !pip install pandas !ls -la # 自动重新加载修改过的模块(开发库时超有用) %load_ext autoreload %autoreload 2 # 让 matplotlib 图表直接显示在 Notebook 里 %matplotlib inline
#推荐插件和扩展
JupyterLab 扩展:
jupyterlab-git:在 JupyterLab 里做 Git 操作jupyterlab-lsp:代码补全和语法检查jupyterlab-code-formatter:自动格式化代码(black / autopep8)
Classic Notebook 扩展(通过 jupyter_contrib_nbextensions):
- Table of Contents:自动生成目录
- Variable Inspector:查看所有变量
- ExecuteTime:显示每个 Cell 的执行时间
#什么时候该换别的工具
Jupyter 不是万能的。遇到下面这些场景,换工具会更舒服:
| 场景 | 更好的选择 | 原因 |
|---|---|---|
| 多人实时协作做数据分析 | Hex | 专门为团队协作设计,版本控制和权限管理都更成熟 |
| 写生产级 Python 项目 | VS Code / PyCharm | 调试器、重构工具、测试集成都比 Notebook 强 |
| SQL 为主的数据探索 | DuckDB + CLI | 不需要 Python 的开销,直接跑 SQL 更快 |
| 大规模数据处理 pipeline | Airflow / Dagster | Notebook 不适合调度和监控 |
| 快速做数据 dashboard | Streamlit / Gradio | 比在 Notebook 里用 widget 方便得多 |
| 纯 Markdown 写技术笔记 | Obsidian / Notion | Notebook 的 Markdown 体验一般 |
一个常见的成长路径:Jupyter 探索和验证想法 → 验证通过后把代码整理成 .py 模块 → 用正式的工程工具部署。不要试图在 Notebook 里完成所有事情。
#安装和上手
bash# 最简单的方式 pip install jupyterlab jupyter lab # 或者用 conda conda install -c conda-forge jupyterlab # 如果只想要经典版 pip install notebook jupyter notebook
打开浏览器,默认地址 http://localhost:8888,就能开始用了。
如果连 Python 环境都不想配,直接用 Google Colab↗——打开浏览器就能写代码,零配置。
#相关资源
- Hex - 团队协作数据分析平台
- DuckDB - 嵌入式分析数据库
- Pandas - Python 数据分析库
- Jupyter 官网:https://jupyter.org↗
- JupyterLab 文档:https://jupyterlab.readthedocs.io↗
- Google Colab:https://colab.research.google.com↗
- nbstripout:https://github.com/kynan/nbstripout↗
- jupytext:https://github.com/mwouts/jupytext↗

