Dify 最值钱的三个功能是 Workflow 工作流、RAG 知识库和 Agent 智能体。把这三个搞明白,基本上能覆盖 80% 的 AI 应用场景。
Workflow:拖拽搭建 AI 流水线
Dify 的 Workflow 编辑器是一个无限画布,你把各种节点拖上去、连线、配参数,一条 AI 流水线就搭好了。
核心节点类型:
| 节点 | 作用 | 使用频率 |
|---|---|---|
| LLM | 调用大模型 | 几乎每个流程都用 |
| Knowledge Retrieval | 查询 RAG 知识库 | 做问答类应用必用 |
| Question Classifier | LLM 驱动的意图分类 | 多分支路由 |
| If/Else | 条件判断分支 | 逻辑控制 |
| Code | 执行 Python 或 Node.js | 数据清洗、格式转换 |
| HTTP Request | 调外部 REST API | 对接第三方服务 |
| Template | Jinja2 模板渲染 | 拼接输出文本 |
| Agent | 自主推理 + 工具调用 | 复杂决策场景 |
| Human Input | 暂停等人工审核 | v1.13 新增,审批流程 |
一个典型的客服 Workflow 长这样:
Start → Question Classifier → [产品咨询] → Knowledge Retrieval → LLM → Answer
→ [退换货] → HTTP Request (查订单) → LLM → Answer
→ [投诉] → Human Input → LLM → Answer
实用技巧:Workflow 分两种——Chatflow(带对话记忆,适合聊天场景)和 Workflow(无状态,适合批量任务)。如果你的应用需要多轮对话,选 Chatflow;如果是定时跑的数据处理管道,选 Workflow。
RAG 知识库:让 AI 读懂你的文档
RAG(Retrieval-Augmented Generation)是让 AI 基于你自己的文档回答问题的技术。Dify 把整个 RAG 流程封装好了:上传文档 → 自动分块 → 向量化 → 存入向量数据库 → 检索 → 注入 LLM 上下文。
支持的文件格式:TXT、Markdown、PDF、HTML、XLSX、DOCX、CSV、PPTX、EPUB——基本上办公文档都能吃。单文件上限 15 MB,可以改配置放大。
三种分块策略:
- General(通用):按分隔符和长度切块,大部分场景够用
- Parent-Child(父子):小块精确匹配,大块提供上下文,检索精度更高
- Q&A:适合 FAQ 表格类文档,按问答对切分
# 通过 API 创建知识库并上传文档
import requests
headers = {"Authorization": "Bearer YOUR_API_KEY"}
# 创建知识库
resp = requests.post("http://localhost/v1/datasets", headers=headers,
json={"name": "产品手册"})
dataset_id = resp.json()["id"]
# 上传文档
with open("manual.pdf", "rb") as f:
requests.post(f"http://localhost/v1/datasets/{dataset_id}/document/create-by-file",
headers=headers,
files={"file": f},
data={"indexing_technique": "high_quality",
"process_rule": '{"mode": "automatic"}'})
检索模式:向量搜索(语义匹配)、全文搜索(关键词匹配)、混合搜索(两者结合 + Rerank 重排序)。我建议直接用混合搜索——精度最高,速度也没慢多少。
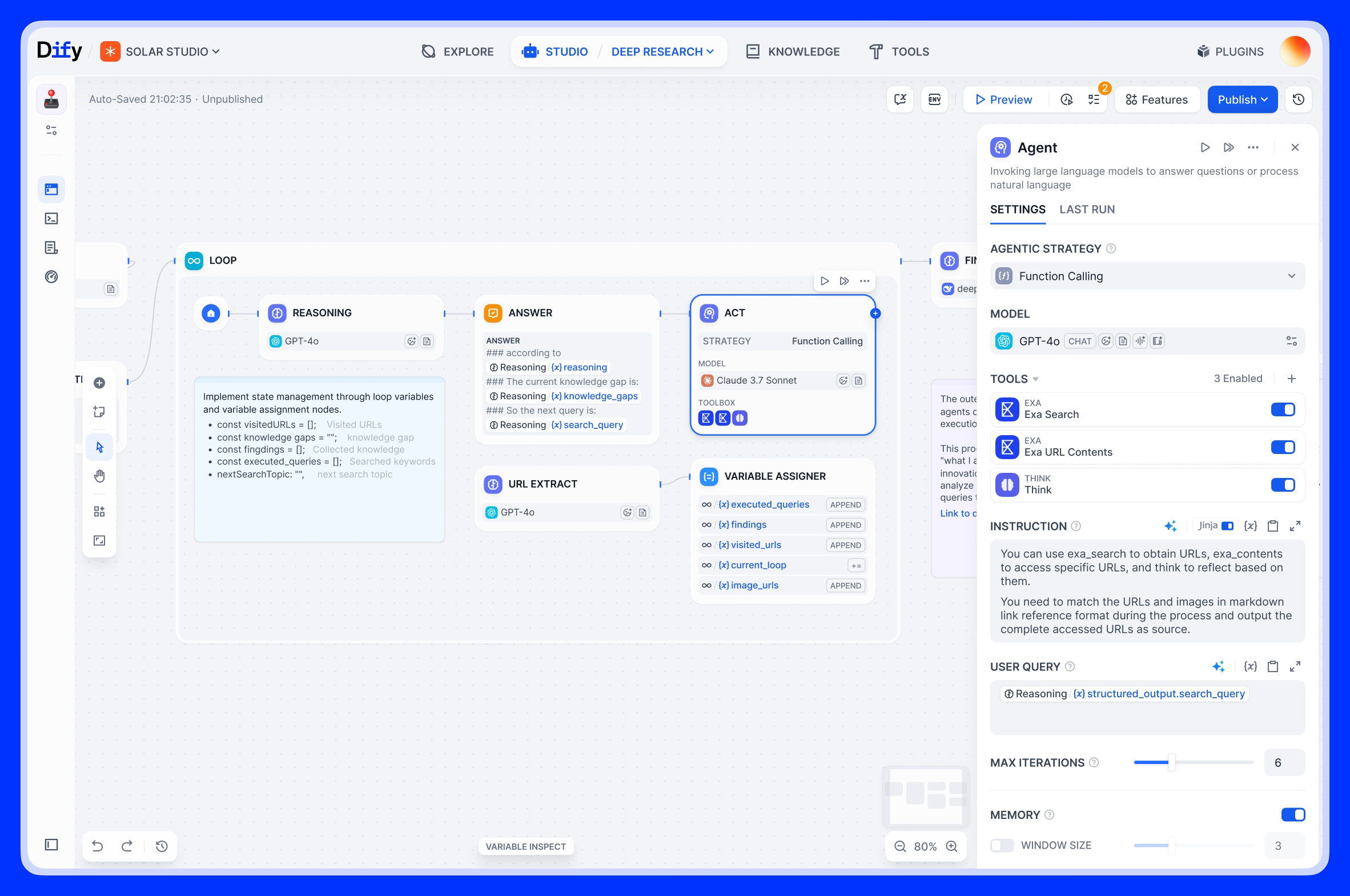
Agent 智能体:让 AI 自己决定该干什么
Agent 不是按你设计的固定流程走,而是 AI 自己判断该调用什么工具、该执行什么步骤。
两种推理策略:
- Function Calling:模型一次性判断意图、选工具、提取参数。速度快,适合意图明确的场景
- ReAct:模型交替"思考"和"行动",一步一步推进。适合需要多轮推理的复杂任务
工具类型:
- 内置工具:Google 搜索、计算器、DALL-E 生图、天气查询等 50+ 个
- 自定义 API 工具:写一个 OpenAPI Schema,Dify 自动帮你调
- 子工作流工具:把另一个 Dify Workflow 当工具调用,实现 Agent 套 Workflow
# 自定义工具的 OpenAPI Schema 示例
openapi: 3.0.0
info:
title: 订单查询
version: 1.0.0
paths:
/api/orders/{orderId}:
get:
summary: 根据订单号查询订单状态
parameters:
- name: orderId
in: path
required: true
schema:
type: string
responses:
'200':
description: 订单信息
Agent 搭配 RAG 知识库和自定义工具,基本上能处理大部分企业内部的智能问答需求。