Llama 3
Llama 3 overview
TL;DR(中文)
Llama 3是 Meta 发布的一系列LLM(包含 8B 与 70B 的 pre-trained 与 instruction-tuned variants),常见用法是作为 open-weight 的通用模型基座。- 选型时不要只看 benchmark:还需要看 context length、latency/cost、tool support、以及你自己的
evaluation(最好有小规模回归集)。 - 如果你在做
RAG/ agentic workflow:建议把 “回答 + evidence” 输出格式写死,并在提示里强调 “no fabrication”。
中文导读(术语保留英文)
这页主要总结 Llama 3 的架构要点与性能对比,并给出进一步阅读的来源。你可以把它当作:
- 了解
Llama 3的核心技术参数(tokenizer、context length、post-training pipeline) - 建立一个“候选模型”认知(与
Gemma、Mistral、Gemini、Claude等做横向对比)
如果你的目标是落地应用,建议额外补做:
- 为你的业务场景写 10-50 条
evaluation样本(含可验收标准) - 用同一套 prompts 对比不同 models 的表现与成本
- 记录失败模式(hallucination、format drift、tool misuse),迭代 prompt 与 guardrails
Original (English)
Meta recently introduced their new family of large language models (LLMs) called Llama 3. This release includes 8B and 70B parameters pre-trained and instruction-tuned models.
Llama 3 Architecture Details
Here is a summary of the mentioned technical details of Llama 3:
- It uses a standard decoder-only transformer.
- The vocabulary is 128K tokens.
- It is trained on sequences of 8K tokens.
- It applies grouped query attention (GQA)
- It is pretrained on over 15T tokens.
- It involves post-training that includes a combination of SFT, rejection sampling, PPO, and DPO.
Performance
Notably, Llama 3 8B (instruction-tuned) outperforms Gemma 7B and Mistral 7B Instruct. Llama 3 70 broadly outperforms Gemini Pro 1.5 and Claude 3 Sonnet and falls a bit behind on the MATH benchmark when compared to Gemini Pro 1.5.
 Source: Meta AI
Source: Meta AI
The pretrained models also outperform other models on several benchmarks like AGIEval (English), MMLU, and Big-Bench Hard.
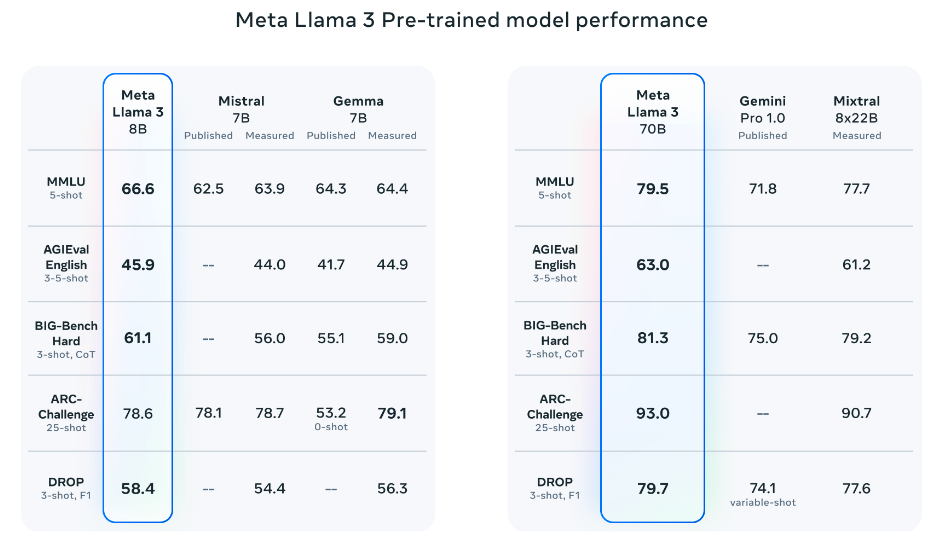 Source: Meta AI
Source: Meta AI
Llama 3 400B
Meta also reported that they will be releasing a 400B parameter model which is still training and coming soon! There are also efforts around multimodal support, multilingual capabilities, and longer context windows in the pipeline. The current checkpoint for Llama 3 400B (as of April 15, 2024) produces the following results on the common benchmarks like MMLU and Big-Bench Hard:
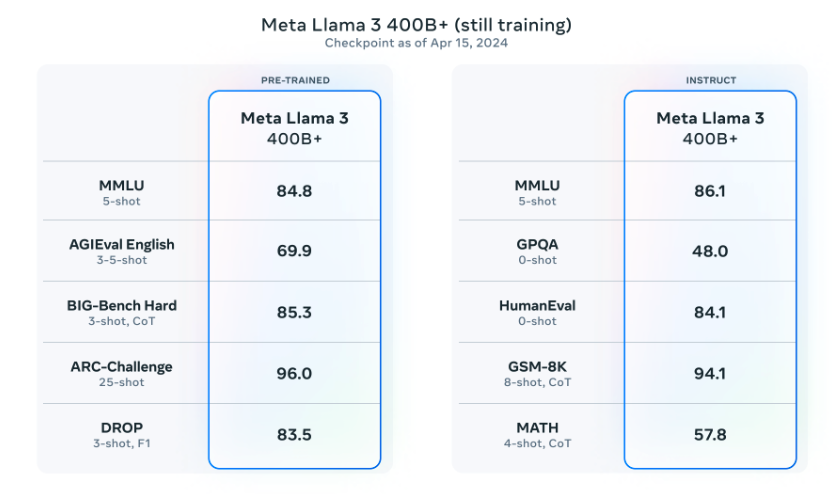 Source: Meta AI
Source: Meta AI
The licensing information for the Llama 3 models can be found on the model card.
Extended Review of Llama 3
Here is a longer review of Llama 3:
https://www.youtube.com/embed/h2aEmciRd6U?si=m7-xXu5IWpB-6mE0