Active-Prompt
Select demonstrations by uncertainty for CoT prompting
Chain-of-thought (CoT) methods rely on a fixed set of human-annotated exemplars. The problem? Those exemplars might not be the most effective ones for different tasks. To address this, Diao et al. (2023) proposed Active-Prompt, a new approach that adapts LLMs to different task-specific example prompts (annotated with human-designed CoT reasoning).
Here's the method illustrated. Step one: query the LLM with or without a few CoT examples. Generate k possible answers for a set of training questions. Compute an uncertainty metric based on those k answers (using disagreement). Select the most uncertain questions for human annotation. Then use the new annotated exemplars for inference on each question.
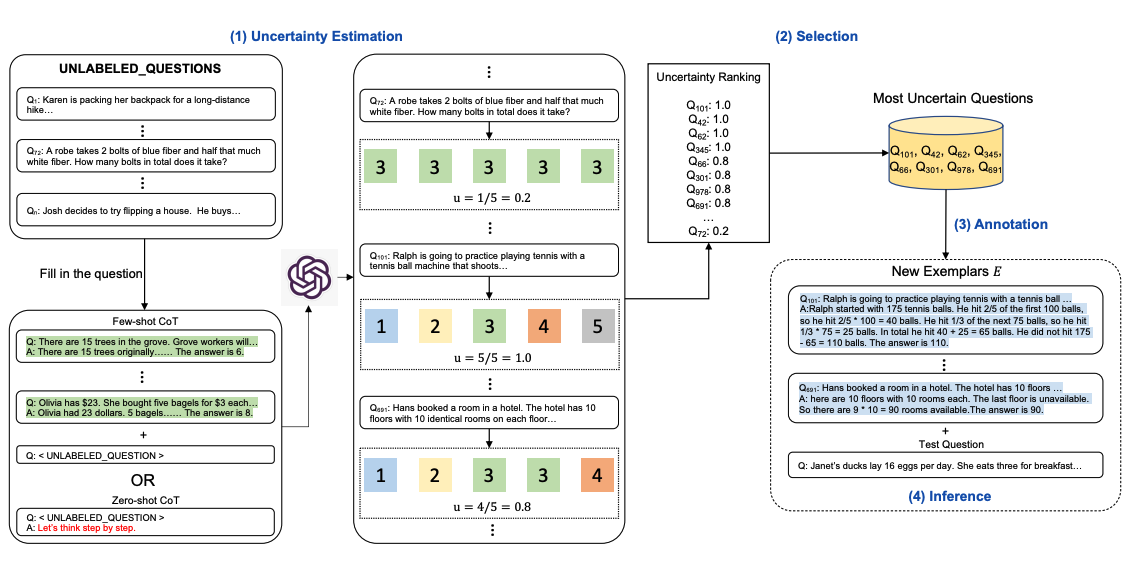
Image source: Diao et al. (2023)
Core Idea
The problem with traditional CoT: all tasks share the same set of hand-annotated examples, but different tasks have different hard parts. Fixed examples can't cover every scenario. Active-Prompt's key insight: let the model tell you which questions are hardest, then prioritize annotating those as examples.
This borrows from active learning -- instead of randomly picking training samples, you pick the ones the model is most "confused" about. Minimum annotation effort, maximum performance gain.
Four-Step Process
Step 1: Uncertainty Estimation
First, use the LLM to generate k answers for each training question (e.g., k=5). Multiple samples let you observe how consistent the model is on each question.
Question: If 3 times a number minus 7 equals 20, what is the number?
Sample 1: 3x - 7 = 20, 3x = 27, x = 9 → Answer: 9
Sample 2: 3x - 7 = 20, 3x = 27, x = 9 → Answer: 9
Sample 3: 20 + 7 = 27, 27 / 3 = 9 → Answer: 9
Sample 4: 3x = 20 + 7 = 27, x = 9 → Answer: 9
Sample 5: 3x - 7 = 20, x = 9 → Answer: 9
→ Disagreement: 0 (all answers agree, model is confident)
Question: A train takes 3 hours from station A to B. From B to C, the speed is 1.5x
and the distance is 2x. How many hours total from A to C?
Sample 1: AB 3hrs, BC = 2d/(1.5v) = 4hrs, total 7hrs → Answer: 7
Sample 2: BC speed 1.5x distance 2x, time = 2/1.5 × 3 = 4hrs, total 7 → Answer: 7
Sample 3: BC = 2 × distance, speed 1.5×, time = 2d/1.5v = 2/(1.5) × 3 = 4, → Answer: 7
Sample 4: 1.5x speed for 2x distance, needs 2/1.5 = 1.33x time = 4hrs, total 5 → Answer: 5
Sample 5: 3 + (2 × 3)/(1.5) = 3 + 4 = 7 → Answer: 7
→ Disagreement: 0.2 (one answer disagrees, model isn't fully confident)
Step 2: Select the Most Uncertain Questions
Rank by uncertainty (disagreement) from high to low. Pick the top n questions. These are the ones the model struggles with most -- and they're the most valuable to annotate.
The paper uses several uncertainty metrics:
- Disagreement: proportion of different answers among k samples
- Entropy: information entropy of the answer distribution
- Variance: for numerical answers, the variance across answers
Step 3: Human Annotation
For the selected most-uncertain questions, human annotators provide detailed CoT reasoning. Since you only need to annotate a small number of high-value questions (typically 4-8), the annotation cost is much lower than annotating everything.
Step 4: Inference
Use the newly annotated exemplars as few-shot examples for inference on all questions. Because these examples are "hand-picked" based on model weaknesses, they typically deliver better results.
Experimental Results
Active-Prompt achieved significant improvements across multiple reasoning benchmarks:
| Benchmark | CoT | Active-Prompt | Improvement |
|---|---|---|---|
| GSM8K (math) | 74.4% | 78.0% | +3.6% |
| AQuA (algebra) | 52.4% | 55.1% | +2.7% |
| SVAMP (math) | 79.0% | 82.3% | +3.3% |
| CSQA (commonsense) | 73.5% | 76.2% | +2.7% |
| StrategyQA | 65.4% | 69.0% | +3.6% |
Note: Results based on code-davinci-002. See the original paper for exact numbers.
Key findings:
- Uncertainty-selected examples consistently outperformed randomly selected ones
- Even with a tiny annotation budget (4-8 examples), Active-Prompt delivered significant gains
- Different uncertainty metrics (disagreement vs. entropy) performed similarly -- disagreement is the simplest and most effective choice
Practical Application Guide
When to Use Active-Prompt?
Active-Prompt works best when:
- Annotation budget is limited: You can only annotate a few examples and need each one to count
- Tasks are highly specific: Generic examples don't work well, you need domain-specific customization
- There's a clear distribution of hard problems: Certain question types consistently trip up the model
Simplified Practice Workflow
You don't need to implement the full paper pipeline for daily use. Here's a simplified approach:
Step 1: Test your LLM on your question set, find questions it frequently gets wrong
Step 2: Write detailed CoT examples for these "error-prone" questions
Step 3: Put those examples into your few-shot prompt
Step 4: Verify the new prompt's performance on the full test set
Comparison with Other Methods
| Method | Example Selection Strategy | Best For |
|---|---|---|
| Few-shot CoT | Random or manual | General tasks |
| Auto-CoT | Cluster then auto-generate | Large-scale automation |
| Active-Prompt | Uncertainty-driven selection | Precise optimization, limited budget |
| Self-Consistency | Sample multiple, majority vote | Improving single-question accuracy |
Self-Check Checklist
- Did you do sufficient uncertainty estimation (at least k=5 samples)?
- Do the selected annotation questions cover the main error types?
- Is the annotated CoT reasoning detailed and logically clear?
- Did you confirm the improvement on a validation set?
References
- Active Prompting with Chain-of-Thought for Large Language Models (Diao et al., 2023)
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Wei et al., 2022)