ReAct
Reasoning + Acting: interact with tools and environments
Yao et al., 2022 introduced a framework where LLMs generate reasoning traces and task-specific actions in an interleaved manner.
Generating reasoning traces lets the model induce, track, and update action plans -- even handle exceptions. Action steps allow interaction with external sources (like knowledge bases or environments) to gather information.
The ReAct framework lets LLMs interact with external tools to retrieve additional information, leading to more reliable and grounded responses.
Results show that ReAct outperforms several state-of-the-art baselines on both language and decision-making tasks. ReAct also improves human interpretability and trustworthiness of LLMs. Overall, the authors found the best approach combines ReAct with chain-of-thought (CoT), using both internal knowledge and externally retrieved information during reasoning.
How Does It Work?
ReAct is inspired by the synergy between "acting" and "reasoning" -- the same synergy that lets humans learn new tasks and make decisions.
CoT prompting showed that LLMs can generate reasoning traces for arithmetic, commonsense reasoning, and other tasks (Wei et al., 2022). But it suffers from lack of access to the external world and inability to update its knowledge, leading to fact hallucination and error propagation.
ReAct is a general paradigm that combines reasoning and acting with LLMs. It prompts LLMs to generate both verbal reasoning traces and actions for a task. This lets the system dynamically create, maintain, and adjust action plans while also interacting with external environments (e.g., Wikipedia) to incorporate additional information. Here's an example showing the different steps involved in answering a question:

Image source: Yao et al., 2022
In the example above, we pass a question from HotpotQA as the prompt:
Besides the Apple Remote, what other devices can control the program the Apple Remote was originally designed to interact with?
Quick note: In-context examples are also added to the prompt, but we've left them out here for simplicity. The model generates "task-solving trajectories" (Thought, Action). Obs corresponds to observations from the environment it interacts with (e.g., a search engine). Essentially, ReAct retrieves information to support reasoning, and reasoning helps determine what to retrieve next.
ReAct Prompting
To better illustrate how ReAct prompting works, let's follow the paper's example.
Step one: select cases from the training set (e.g., HotPotQA) and compose ReAct-format trajectories. These serve as few-shot examples in the prompt. Trajectories consist of multiple Thought-Action-Observation steps. Free-form thoughts handle different tasks like decomposing questions, extracting information, commonsense/arithmetic reasoning, guiding search formulation, and synthesizing final answers.
Here's a ReAct prompt example (from the paper, shortened to one example for simplicity):
Question What is the elevation range for the area that the eastern sector of the Colorado orogeny extends into?
Thought 1 I need to search Colorado orogeny, find where its eastern sector extends to, then find the elevation range of that area.
Action 1 Search [Colorado orogeny]
Observation 1 The Colorado orogeny was an episode of mountain building in Colorado and surrounding areas.
Thought 2 It doesn't mention the eastern sector. I need to look up the eastern sector.
Action 2 Lookup [eastern sector]
Observation 2 (Result 1 / 1) The eastern sector extends into the High Plains and is called the Central Plains orogeny.
Thought 3 The eastern sector extends into the High Plains. I need to search High Plains and find its elevation range.
Action 3 Search [High Plains]
Observation 3 High Plains can refer to different regions.
Thought 4 I need to search High Plains (United States).
Action 4 Search [High Plains (United States)]
Observation 4 The High Plains is a subregion of the Great Plains. From east to west, elevation ranges from about 1,800 to 7,000 feet (550 to 2,130 m).[3]
Thought 5 The High Plains elevation ranges from 1,800 to 7,000 feet, so the answer is 1,800 to 7,000 feet.
Action 5 Finish [1,800 to 7,000 feet]
...
Different prompt setups are used for different task types. For reasoning-heavy tasks (like HotpotQA), multiple Thought-Action-Observation steps form the trajectory. For decision-making tasks involving many actions, thoughts are used less frequently.
Results on Knowledge-Intensive Tasks
The paper first evaluated ReAct on knowledge-intensive reasoning tasks like question answering (HotPotQA) and fact verification (Fever). PaLM-540B was the base model.
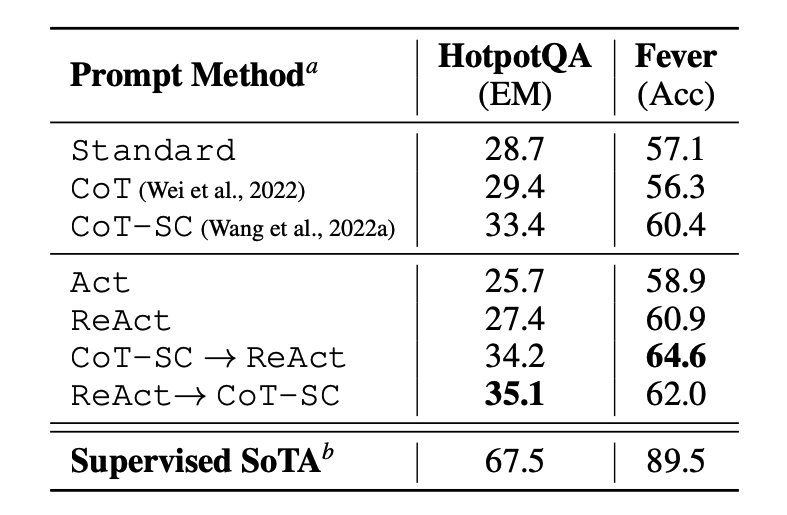
Image source: Yao et al., 2022
Results across HotPotQA and Fever with different prompting methods show that ReAct generally outperforms Act (actions only).
ReAct outperforms CoT on Fever but trails CoT on HotpotQA. The paper has detailed error analysis. In short:
- CoT suffers from fact hallucination
- ReAct's structural constraints reduce its flexibility in formulating reasoning steps
- ReAct relies heavily on retrieved information; uninformative search results derail reasoning and make recovery difficult
Prompting methods that combine and support switching between ReAct and CoT + Self-Consistency generally outperform all other approaches.
Results on Decision-Making Tasks
The paper also reports ReAct results on decision-making tasks, evaluated on ALFWorld (text-based game) and WebShop (online shopping environment). Both involve complex environments requiring reasoning to act and explore effectively.
Note that while the ReAct prompt design differs significantly across these tasks, the core idea stays the same: combine reasoning and acting. Here's an ALFWorld example with ReAct prompting:
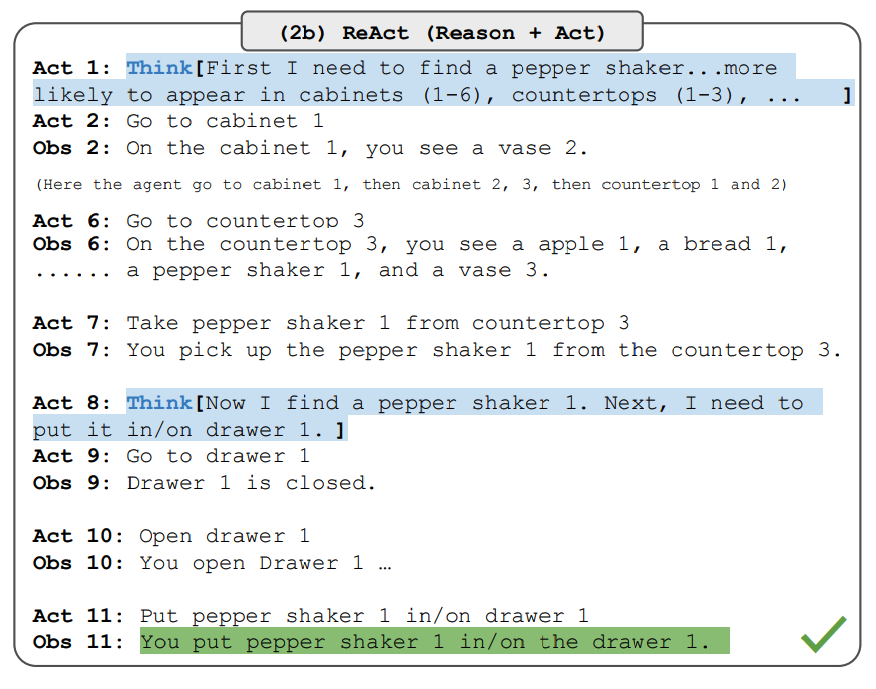
Image source: Yao et al., 2022
ReAct outperforms Act on both ALFWorld and Webshop. Act without thinking can't properly decompose goals into subgoals. Although ReAct shows reasoning advantages in these tasks, current prompt-based methods are still far from human expert performance.
Check the paper for detailed results.
Using ReAct with LangChain
Here's a high-level example of how ReAct works in practice. We'll use OpenAI as the LLM and LangChain, which has built-in functionality for building agents that leverage the ReAct framework, combining LLMs with various tools.
First, install and import the necessary libraries:
%%capture
# Update or install required libraries
!pip install --upgrade openai
!pip install --upgrade langchain
!pip install --upgrade python-dotenv
!pip install google-search-results
# Import libraries
from langchain.llms import OpenAI
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from dotenv import load_dotenv
load_dotenv()
# Load API keys (make sure you have them set in your environment).
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
Now configure the LLM, tools, and agent that lets us combine the ReAct framework with the LLM and other tools. We're using a search API for external information and the LLM as a math tool.
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)
tools = load_tools(["google-serper", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
Once configured, we run the agent with the desired query. Note that we're not providing few-shot examples here, unlike the paper.
agent.run(
"Who is Olivia Wilde's boyfriend? What is 0.23 power of his current age?"
)
The chain execution looks like this:
> Entering new AgentExecutor chain...
I need to find who Olivia Wilde's boyfriend is and compute 0.23 power of his age.
Action: Search
Action Input: "Olivia Wilde boyfriend"
Observation: After her split with Jason Sudeikis, Olivia Wilde started dating Harry Styles.
Thought: I need to find Harry Styles' age.
Action: Search
Action Input: "Harry Styles age"
Observation: 29
Thought: I need to compute 29^0.23.
Action: Calculator
Action Input: 29^0.23
Observation: Answer: 2.169459462491557
Thought: Now I know the final answer.
Final Answer: Harry Styles is Olivia Wilde's boyfriend. He is 29 years old. 0.23 power of his age is 2.169459462491557.
> Finished chain.
Output:
"Harry Styles is Olivia Wilde's boyfriend. He is 29 years old. 0.23 power of his age is 2.169459462491557."
This example was adapted from the LangChain documentation, all credit to them. We encourage you to explore different combinations of tools and tasks.
You can find the code here: https://github.com/dair-ai/Prompt-Engineering-Guide/blob/main/notebooks/react.ipynb
📚 相关资源
❓ 常见问题
关于本章主题最常被搜索的问题,点击展开答案
ReAct 框架到底是什么?
ReAct(Yao 等人 2022)让 LLM 以交错方式生成「推理轨迹」+「任务特定操作」——也就是 Thought / Action / Observation 循环。Thought 在内部规划,Action 调用外部工具(搜索、计算器),Observation 是返回结果。这样模型既能动态推理,又能跟外部世界交互。
ReAct 和 Chain-of-Thought 区别在哪里?
CoT 只在内部推理,不能查外部信息——结果是事实幻觉、错误传播。ReAct 在 CoT 基础上加了 Action 步骤可以调工具(如 Wikipedia 搜索),把外部观察拉回推理链。论文在 HotpotQA / Fever 上显示:CoT 容易瞎编,ReAct 因为依赖检索结果更稳,但搜索失败时会被卡住。
ReAct 在哪些 benchmark 上被测过?
知识密集任务用 HotpotQA(多跳问答)+ Fever(事实验证),基础模型是 PaLM-540B;决策任务用 ALFWorld(文本游戏)+ WebShop(在线购物环境)。结果:ReAct 在 Fever 上优于 CoT,在 HotpotQA 上落后 CoT;在 ALFWorld 和 WebShop 上都优于纯 Act(无思考)。
ReAct 是 Agent 框架的起源吗?
可以这么说。ReAct 把「Thought-Action-Observation」循环规范化成 LLM 调工具的标准范式,今天 LangChain 的 zero-shot-react-description agent、AutoGPT、OpenAI function calling 都是这套思路的直系演化。要构建能调 search / calculator / DB 的 LLM 应用,ReAct 是最早被工业化的模板。
ReAct 提示要怎么写?
从训练集(如 HotpotQA)选案例,组成 ReAct 格式轨迹作为少样本示例。每条示例由多组 Thought-Action-Observation 步骤构成,自由形式的 Thought 用来分解问题、抽取信息、推理;Action 形如 `Search[Colorado orogeny]` 或 `Lookup[eastern sector]`;最后用 `Finish[answer]` 收尾。决策任务可以减少 Thought。