APE
Automatic Prompt Engineer: auto-generate and select instructions
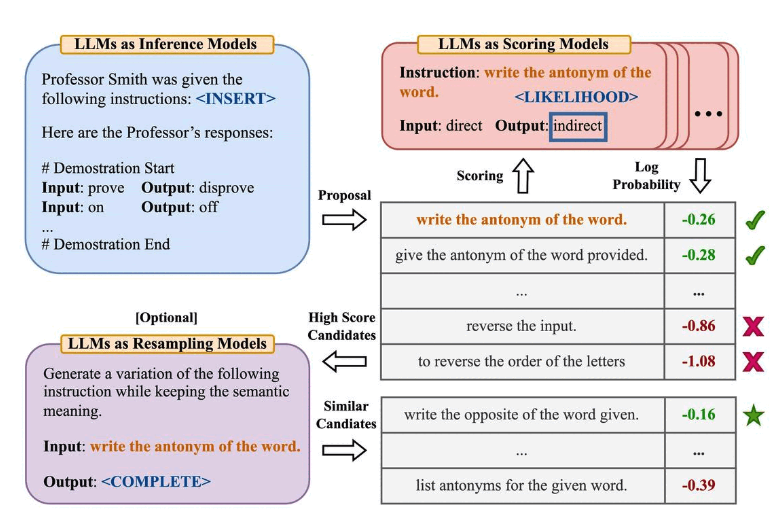
Image source: Zhou et al. (2022)
Zhou et al. (2022) proposed Automatic Prompt Engineer (APE), a framework for automatic instruction generation and selection. The instruction generation problem is framed as natural language synthesis -- using LLMs as black-box optimizers to generate and search candidate solutions.
The first step involves a large language model (as an inference model) that receives output demonstrations to generate instruction candidates for the task. These candidates guide the search process. A target model executes the instructions, and the best instruction is selected based on computed evaluation scores.
APE discovered a zero-shot CoT prompt that's better than the human-designed "Let's think step by step" prompt (Kojima et al., 2022).
The prompt "Let's work this out in a step by step way to be sure we have the right answer." triggers chain-of-thought reasoning and improved performance on MultiArith and GSM8K benchmarks:

Image source: Zhou et al. (2022)
This paper touches on an important topic in prompt engineering: automatically optimizing prompts. While we don't go deep into this here, here are some key papers if you're interested:
- Prompt-OIRL - Uses offline inverse reinforcement learning to generate query-dependent prompts.
- OPRO - Introduces the idea of using LLMs to optimize prompts: telling LLMs to "take a deep breath" improves math performance.
- AutoPrompt - Proposes a gradient-guided search method for automatically creating prompts for various tasks.
- Prefix Tuning - A lightweight fine-tuning alternative that prepends trainable continuous prefixes for NLG tasks.
- Prompt Tuning - Proposes learning soft prompts through backpropagation.
📚 相关资源
❓ 常见问题
关于本章主题最常被搜索的问题,点击展开答案
APE 是什么?为什么叫「自动提示工程师」?
Zhou 等人 2022 提出,把指令生成问题转成「自然语言合成 + 黑盒优化」。一个 LLM 作为推理模型读输入输出示例反推候选指令,目标模型执行候选指令打分,按分数选最优——整个过程不需要人写 prompt,所以叫「自动提示工程师」。
APE 找到的最佳 zero-shot CoT 是什么?
原论文最有名的发现:APE 找到的「Let's work this out in a step by step way to be sure we have the right answer.」比 Kojima 等人 2022 手写的「Let's think step by step」在 MultiArith 和 GSM8K 上表现更好。证明 LLM 可以自己优化 prompt——人手写的不一定最优。
APE 跟手动 prompt engineering 比有什么优势?
三点:1) 系统化搜索——能跑数百候选指令而不是凭直觉写两三条;2) 不依赖工程师对任务的偏见;3) 可以基于评估分数迭代。代价是:需要标注好的输入输出对作为评估集,而且每次跑都要消耗大量 token。所以适合「指令一旦优化就长期复用」的场景。
APE 之外还有哪些自动 prompt 优化方法?
原文列了几个关键方向:Prompt-OIRL(离线逆强化学习生成查询相关 prompt)、OPRO(让 LLM「深呼吸」优化数学题)、AutoPrompt(基于梯度搜索)、Prefix Tuning(轻量级 fine-tune 替代)、Prompt Tuning(反向传播学软 prompt)。整体可分两路:search-based(APE/OPRO)vs gradient-based(AutoPrompt/Prefix)。
我没有大量 GPU,能用 APE 吗?
能,但要分清版本。原论文 APE 调用商业 API 评估候选指令,没需要 GPU——只需要预算去跑 N 次推理。GPU 是 Prefix Tuning / Prompt Tuning 这类「软 prompt」方法才需要(要反向传播)。所以小团队可以跑 APE 风格的搜索:写 50-100 个候选 → 在小评估集上跑 → 选最优,整个过程纯 API 调用。