Deep Agents
Deep Agent design: planning, task delegation, retrieval, verification, and iteration
TL;DR
- Most
AI Agentsgo "shallow" when they hit long-chain, multi-step tasks: plans fall apart, context explodes, tool calls get messy, and the final output can't be verified. - "Deep Agents" focus on 5 key capabilities:
Planning,Orchestrator & Sub-agentarchitecture,Context Retrieval,Context Engineering, andVerification. - Making an
AI Agentdeep usually isn't about "stacking more prompts" — it's systems engineering: division of labor, memory, observability, evaluation, and recoverable execution paths.
Core Concepts
"Deep Agents" are basically agentic systems designed for complex tasks. They don't just generate answers — they maintain a long-running plan, delegate subtasks to different sub-agents, write intermediate artifacts to external memory, and use verification to make outputs more reliable.
A common production setup looks like this:
- One
orchestratorowns the master plan and scheduling - Multiple sub-agents focus on specific subtasks (search, coding, analysis, verification, writing)
- External memory (files / notes / vector store / database) stores intermediate results and key facts
How to Apply
If you want to upgrade a "shallow agent" toward a "deep agent," start with these steps:
- Explicit planning: Have the
orchestratoroutput a structured plan, and require status updates at each step (no silent skips). - Separate contexts: Each sub-agent only gets the minimal context it needs (separation of concerns) — this reduces context length risk.
- External memory: Write intermediate artifacts externally (e.g.,
notes/,reports/,facts.json), so later steps reference "files/records" instead of relying on conversation scroll. - Verification gate: Critical conclusions must pass through
LLM-as-a-Judgeor human review. If something's uncertain, explicitly flag the uncertainty. - Observability: Log every tool call, every plan update, every failure and retry reason — this makes iterating on
Context Engineeringmuch easier.
Self-Check Rubric
Planning: Is there an updatable plan? Can it retry/recover? Are skipped steps logged with reasons?Orchestrator & Sub-agent: Are responsibilities clearly defined? Are sub-agent inputs minimized? Can outputs be merged?Context Retrieval: Are key facts written to external memory? Is the retrieval strategy controllable (hybrid / semantic / keyword)?Context Engineering: Are system prompts, tool descriptions, and output schemas explicit enough?Verification: Is there systematicevaluation? Can it catchhallucinationand blockprompt injectioneffects?
Practice
Exercise: Design a minimal architecture for a "Deep Research Agent" (no code required).
- Include at least these sub-agents:
Search Worker,Analyst,Verifier. - Describe each sub-agent's input/output, which tools it calls, and which external files store its artifacts.
- Design a
verificationflow: when must a re-search happen? When is human confirmation required?
References
- LangChain: Deep Agents (Labs)
- Anthropic: Writing tools for agents
- Anthropic: Building agents with the Claude Agent SDK
- PromptingGuide: Context Engineering Guide
Original (English)
Most agents today are shallow.
They easily break down on long, multi-step problems (e.g., deep research or agentic coding).
That's changing fast!
We're entering the era of "Deep Agents", systems that strategically plan, remember, and delegate intelligently for solving very complex problems.
We at the DAIR.AI Academy and other folks from LangChain, Claude Code, as well as more recently, individuals like Philipp Schmid, have been documenting this idea.
Here is an example of a deep agent built to power the DAIR.AI Academy's customer support system intended for students to ask questions regarding our trainings and courses:
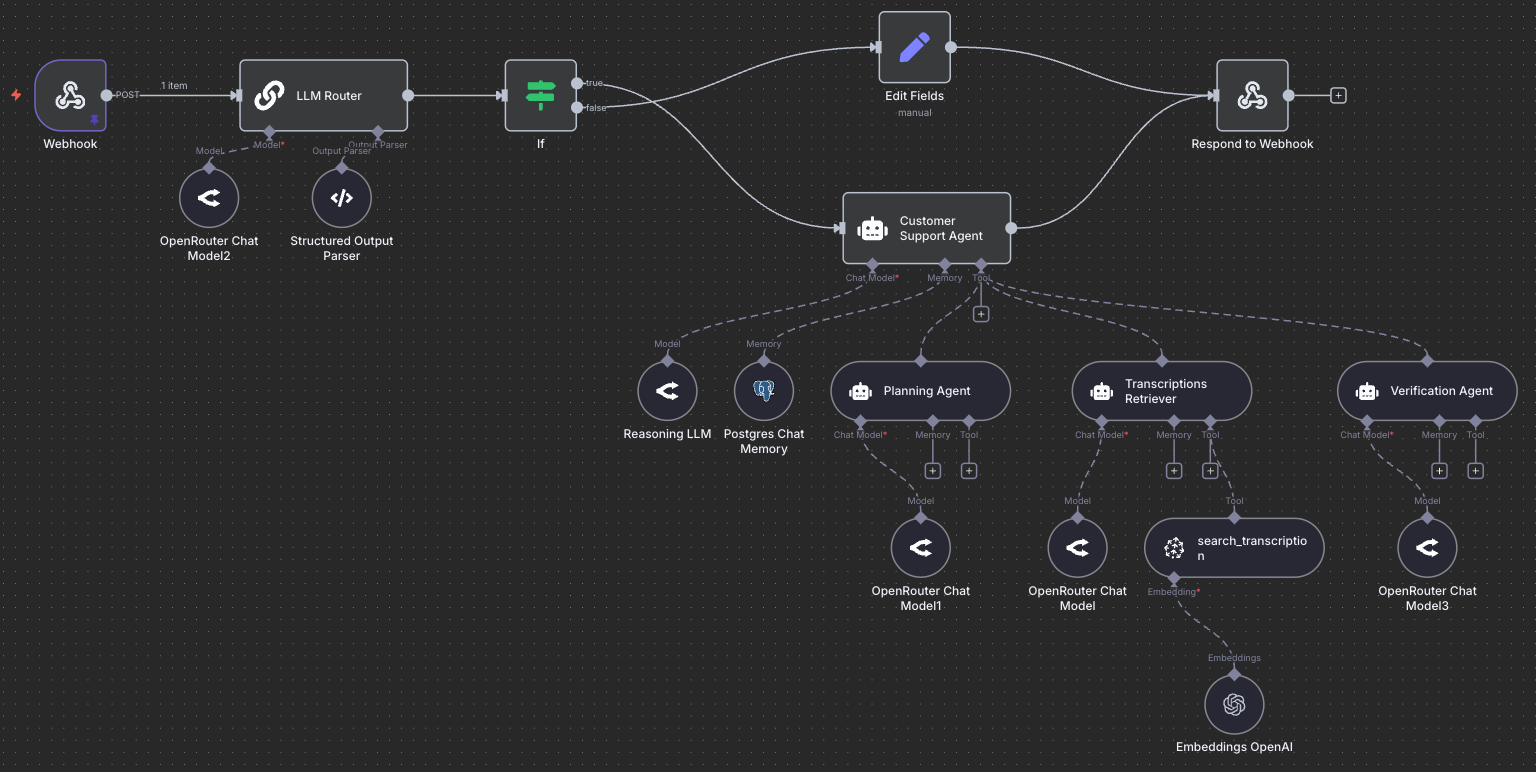
Here's roughly the core idea behind Deep Agents (based on my own thoughts and notes that I've gathered from others):
Planning
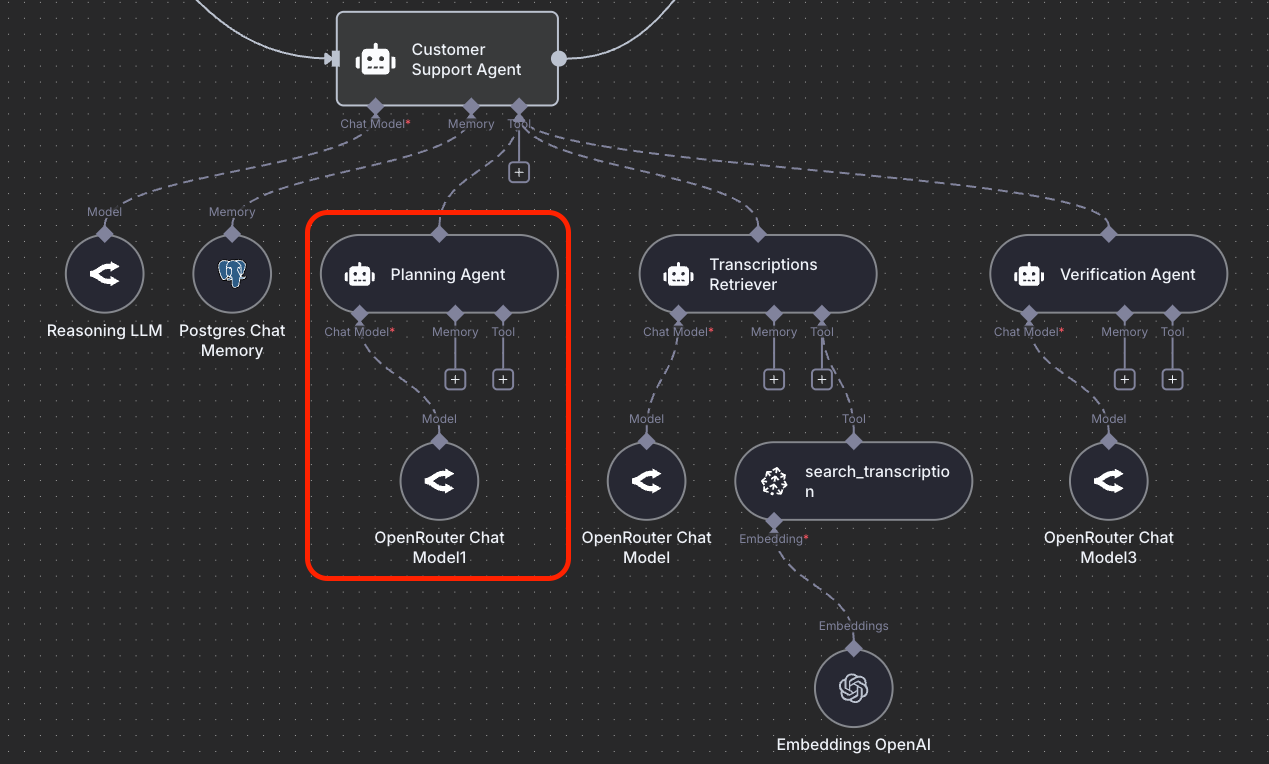
Instead of reasoning ad-hoc inside a single context window, Deep Agents maintain structured task plans they can update, retry, and recover from. Think of it as a living to-do list that guides the agent toward its long-term goal. To experience this, just try out Claude Code or Codex for planning; the results are significantly better once you enable it before executing any task.
We have also written recently on the power of brainstorming for longer with Claude Code, and this shows the power of planning, expert context, and human-in-the-loop (your expertise gives you an important edge when working with deep agents). Planning will also be critical for long-horizon problems (think agents for scientific discovery, which comes next).
Orchestrator & Sub-agent Architecture
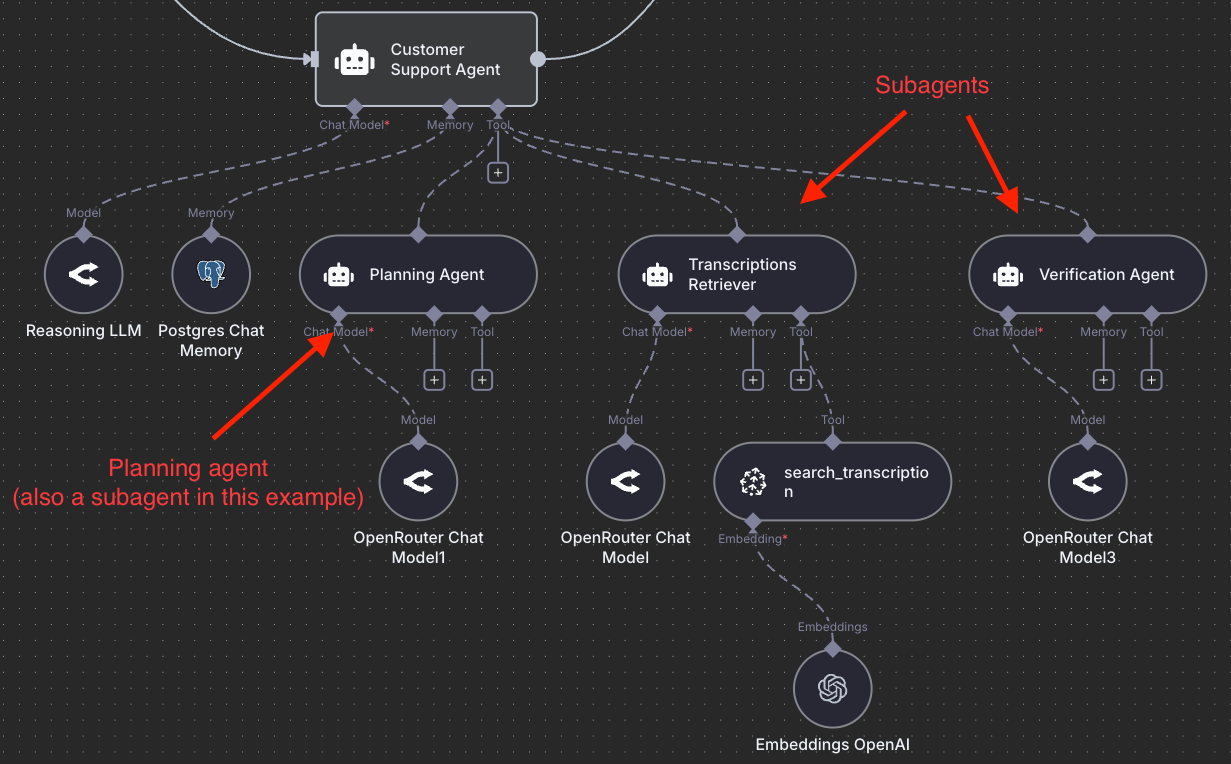
One big agent (typically with a very long context) is no longer enough. I've seen arguments against multi-agent systems and in favor of monolithic systems, but I'm skeptical about this.
The orchestrator-sub-agent architecture is one of the most powerful LLM-based agentic architectures you can leverage today for any domain you can imagine. An orchestrator manages specialized sub-agents such as search agents, coders, KB retrievers, analysts, verifiers, and writers, each with its own clean context and domain focus.
The orchestrator delegates intelligently, and subagents execute efficiently. The orchestrator integrates their outputs into a coherent result. Claude Code popularized the use of this approach for coding and sub-agents, which, it turns out, are particularly useful for efficiently managing context (through separation of concerns).
I wrote a few notes on the power of using orchestrator and subagents here and here.
Context Retrieval and Agentic Search
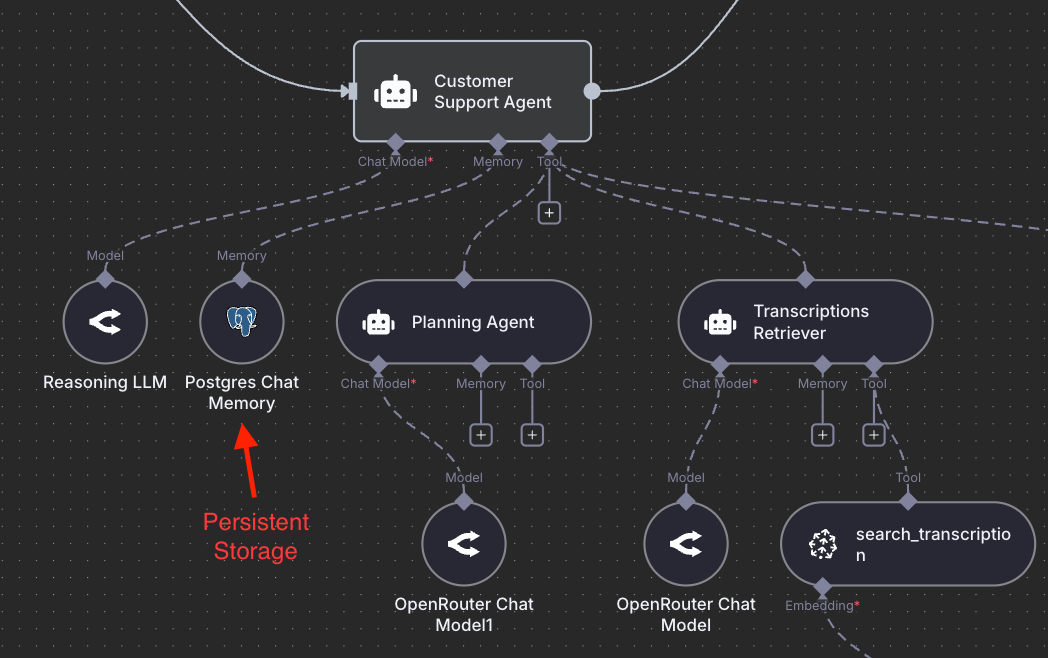
Deep Agents don't rely on conversation history alone. They store intermediate work in external memory like files, notes, vectors, or databases, letting them reference what matters without overloading the model's context. High-quality structured memory is a thing of beauty.
Take a look at recent works like ReasoningBank and Agentic Context Engineering for some really cool ideas on how to better optimize memory building and retrieval. Building with the orchestrator-subagents architecture means that you can also leverage hybrid memory techniques (e.g., agentic search + semantic search), and you can let the agent decide what strategy to use.
Context Engineering
One of the worst things you can do when interacting with these types of agents is underspecified instructions/prompts. Prompt engineering was and is important, but we will use the new term context engineering to emphasize the importance of building context for agents. The instructions need to be more explicit, detailed, and intentional to define when to plan, when to use a sub-agent, how to name files, and how to collaborate with humans. Part of context engineering also involves efforts around structured outputs, system prompt optimization, compacting context, evaluating context effectiveness, and optimizing tool definitions.
Read our previous guide on context engineering to learn more: Context Engineering Deep Dive
Verification
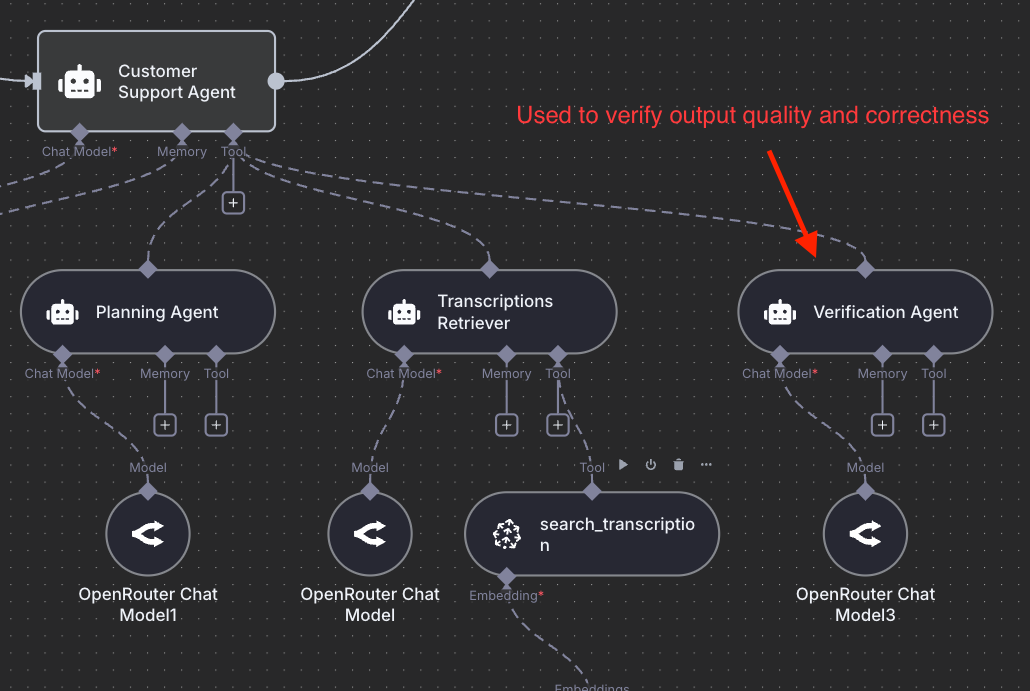
Next to context engineering, verification is one of the most important components of an agentic system (though less often discussed). Verification boils down to verifying outputs, which can be automated (LLM-as-a-Judge) or done by a human. Because of the effectiveness of modern LLMs at generating text (in domains like math and coding), it's easy to forget that they still suffer from hallucination, sycophancy, prompt injection, and a number of other issues. Verification helps with making your agents more reliable and more production-ready. You can build good verifiers by leveraging systematic evaluation pipelines.
Final Words
This is a huge shift in how we build with AI agents. Deep agents also feel like an important building block for what comes next: personalized proactive agents that can act on our behalf. I will write more on proactive agents in a future post.
The figures you see in the post describe an agentic RAG system that students need to build for the course final project.