Reflexion
Self-reflection: reinforce agents with verbal feedback
Reflexion is a framework that reinforces language-based agents through linguistic feedback. According to Shinn et al. (2023), "Reflexion is a new paradigm for 'verbal' reinforcement that parameterizes a policy as an agent's memory encoding paired with an LLM's parameter choices."
At a high level, Reflexion converts environment feedback (free-form language or scalar rewards) into linguistic feedback -- called self-reflection -- that provides context for the LLM agent in the next round. This helps the agent learn quickly and effectively from past mistakes, improving performance on many advanced tasks.
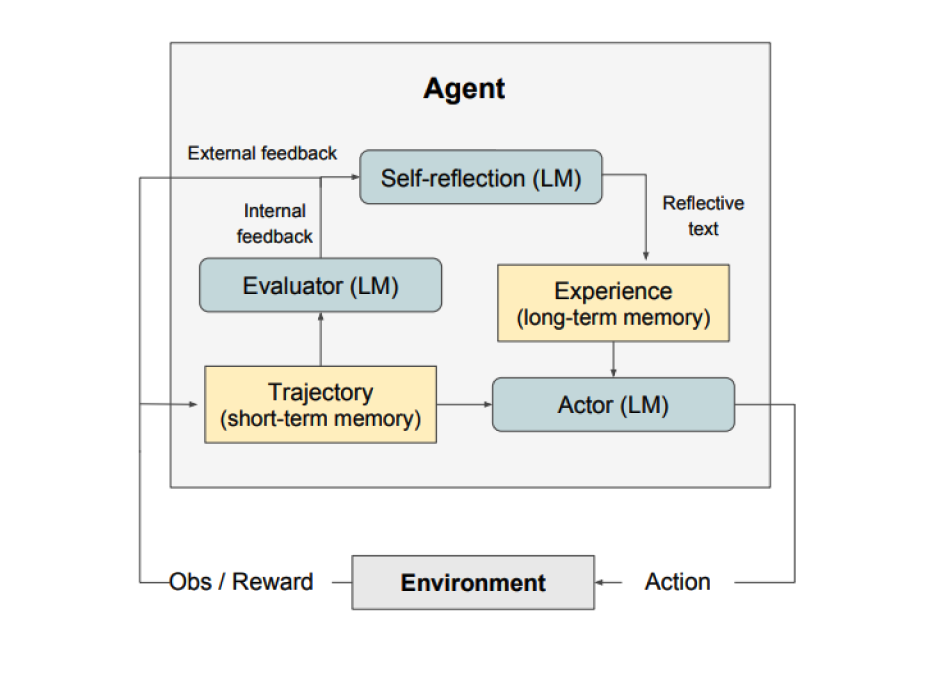
As shown above, Reflexion consists of three distinct models:
- Actor: Generates text and actions based on state observations. The actor takes actions in the environment and receives observations, forming trajectories. Chain-of-Thought (CoT) and ReAct serve as actor models. A memory component is also added to provide additional context.
- Evaluator: Scores the actor's output. Specifically, it takes the generated trajectory (also called short-term memory) as input and outputs a reward score. Different reward functions are used for different tasks (LLM-based and rule-based heuristic rewards for decision tasks).
- Self-Reflection: Generates verbal reinforcement cues to help the actor improve. This role is played by an LLM, producing valuable feedback for future trials. The self-reflection model uses the reward signal, current trajectory, and persistent memory to generate specific and relevant feedback, which is stored in the memory component. The agent leverages these experiences (stored in long-term memory) to rapidly improve its decisions.
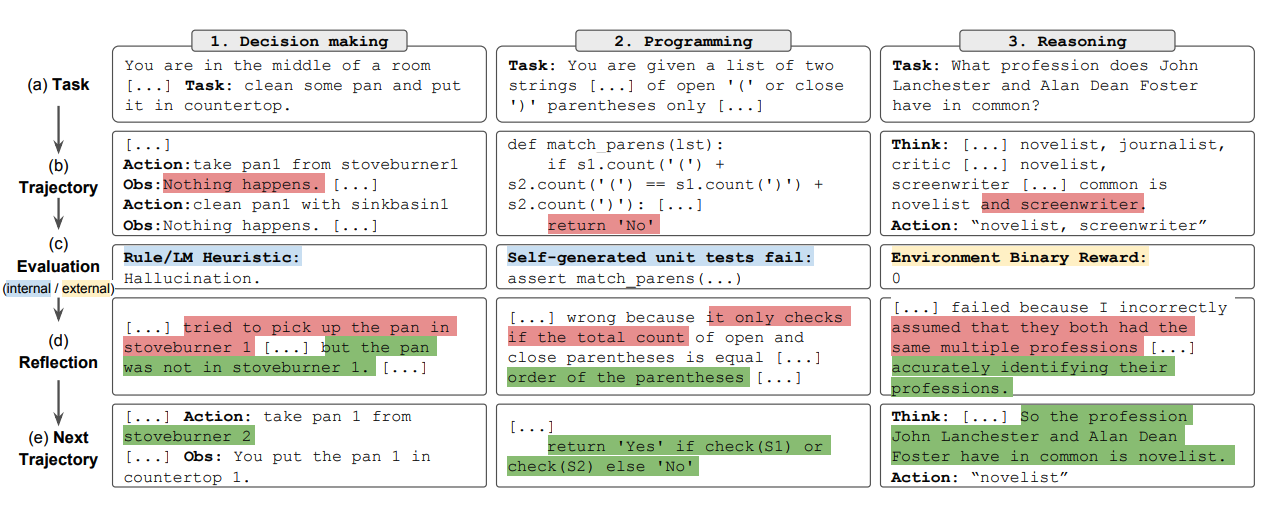
Overall, the key steps in Reflexion are: a) define the task, b) generate a trajectory, c) evaluate, d) perform self-reflection, e) generate the next trajectory. The figure below shows examples of a Reflexion agent learning to iteratively improve its behavior for decision-making, coding, and reasoning tasks. Reflexion extends the ReAct framework by introducing self-evaluation, self-reflection, and memory components.
Results
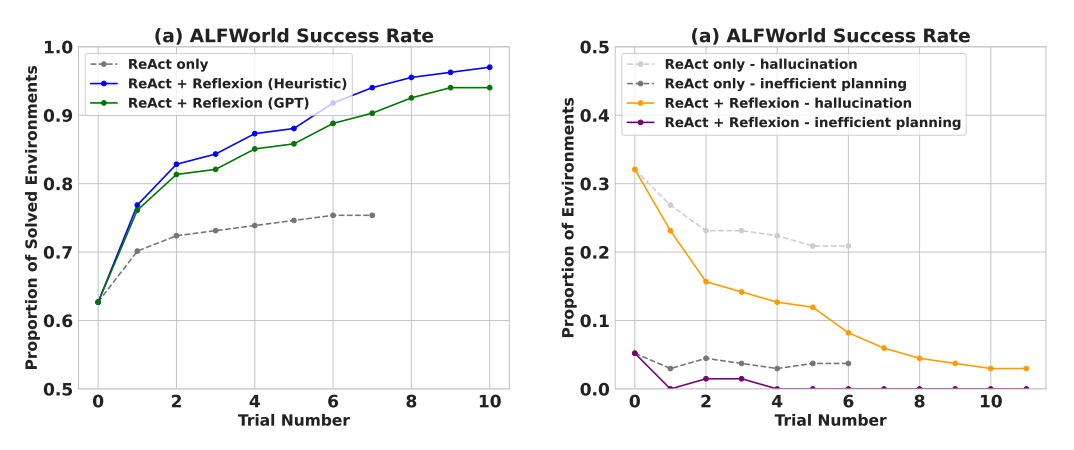
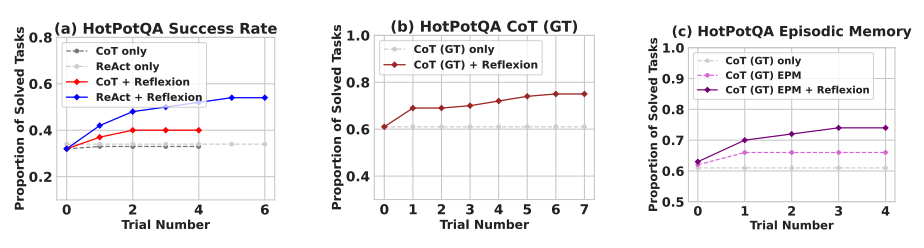
Experiments show that Reflexion significantly improves performance on decision-making tasks in AlfWorld, question reasoning in HotPotQA, and Python programming tasks on HumanEval.
On sequential decision-making (AlfWorld) tasks, ReAct + Reflexion with heuristic and GPT self-evaluation for binary classification completed 130/134 tasks, significantly outperforming ReAct alone.
In just a few learning steps, Reflexion significantly outperformed all baseline methods. For reasoning alone and when adding episodic memory consisting of recent trajectories, Reflexion + CoT outperformed CoT-only and CoT with episodic memory respectively.
As shown in the table below, Reflexion generally outperforms previous SOTA methods when writing Python and Rust code on MBPP, HumanEval, and Leetcode Hard.

When to Use Reflexion?
Reflexion works best when:
-
The agent needs to learn from trial and error: Reflexion is designed to help agents improve by reflecting on past mistakes and incorporating that knowledge into future decisions. It's a natural fit for tasks requiring iterative learning, such as decision-making, reasoning, and programming.
-
Traditional RL methods aren't practical: Conventional reinforcement learning typically needs massive training data and expensive model fine-tuning. Reflexion offers a lightweight alternative that doesn't require fine-tuning the underlying language model, making it more efficient in terms of data and compute.
-
Nuanced feedback is needed: Reflexion uses linguistic feedback, which is more nuanced and specific than scalar rewards in traditional RL. This lets the agent better understand its mistakes and make more targeted improvements in subsequent trials.
-
Interpretability and explicit memory matter: Compared to traditional RL, Reflexion provides a more interpretable and explicit form of episodic memory. The agent's self-reflections are stored in its memory component, making it easier to analyze and understand its learning process.
Reflexion has proven effective on these tasks:
- Sequential decision-making: Improved agent performance on AlfWorld tasks involving navigation and multi-step goals across various environments.
- Reasoning: Improved performance on HotPotQA, a QA dataset requiring multi-document reasoning.
- Programming: Reflexion agents wrote better code on benchmarks like HumanEval and MBPP, achieving SOTA results in some cases.
Some limitations to keep in mind:
- Depends on self-evaluation ability: Reflexion relies on the agent accurately assessing its performance and generating useful reflections. This can be challenging for complex tasks, though it should improve as models get better.
- Long-term memory constraints: Reflexion uses a sliding window with a maximum capacity. For more complex tasks, advanced structures like vector embeddings or SQL databases might work better.
- Code generation limitations: Test-driven development has limitations in specifying accurate input-output mappings (e.g., non-deterministic generator functions and hardware-dependent function outputs).
Image source: Reflexion: Language Agents with Verbal Reinforcement Learning
References
📚 相关资源
❓ 常见问题
关于本章主题最常被搜索的问题,点击展开答案
Reflexion 是什么?为什么叫「口头强化学习」?
Shinn 等人 2023 提出,把环境反馈(自由语言或标量奖励)转成「自我反思」的语言反馈,存到记忆里,下一轮 LLM agent 把它当上下文。不需要更新模型权重——参数化的是「记忆」而不是模型,所以叫口头(verbal)强化学习,是不微调底座模型的轻量替代方案。
Reflexion 框架由哪几个角色组成?
三个:Actor(参与者)基于状态生成文本和动作,常用 CoT 或 ReAct 实现;Evaluator(评估者)对 Actor 输出打奖励分(决策任务用规则启发式或 LLM 评估);Self-Reflection 模型基于奖励信号 + 当前轨迹 + 长期记忆生成语言反馈存进记忆,供下次试验使用。
Reflexion 和 ReAct 是什么关系?
Reflexion 在 ReAct 基础上加了三个东西:自我评估、自我反思、长期记忆。ReAct 是单次 trial 内的 Thought-Action-Observation;Reflexion 把多次 trial 串起来,每次失败后生成「我哪里错了 + 下次怎么改」的语言反思,把它带到下一轮。论文显示 ReAct + Reflexion 在 ALFWorld 上完成 130/134 项任务,显著高于纯 ReAct。
Reflexion 在哪些任务上有效?提升多少?
三类都有效:序列决策(AlfWorld,ReAct + Reflexion 二元分类完成 130/134)、推理(HotPotQA,Reflexion + CoT 优于纯 CoT 和带情景记忆的 CoT)、编程(MBPP / HumanEval / Leetcode Hard 上 Python 和 Rust 代码超越当时 SOTA)。共同特征:任务允许反复试错,错误信号能转成可读语言。
Reflexion 有什么局限?
三个:依赖自我评估能力——复杂任务下 LLM 可能反思错方向;长期记忆用滑动窗口,复杂任务最好上向量库或 SQL;代码生成时硬件相关、非确定性输出(含随机数、时间戳、IO)很难定义清晰的输入输出映射,反思也找不到稳定改进方向。所以不是万能 agent 框架。