Multimodal CoT
A two-stage CoT framework combining vision and text
Zhang et al. (2023) proposed a multimodal chain-of-thought prompting approach. Traditional CoT focuses on the language modality only. Multimodal CoT incorporates both text and vision into a two-stage framework. The first stage involves rationale generation based on multimodal information. The second stage is answer inference, which leverages the generated rationale to arrive at the final answer.
The multimodal CoT model (1B parameters) outperformed GPT-3.5 on the ScienceQA benchmark.
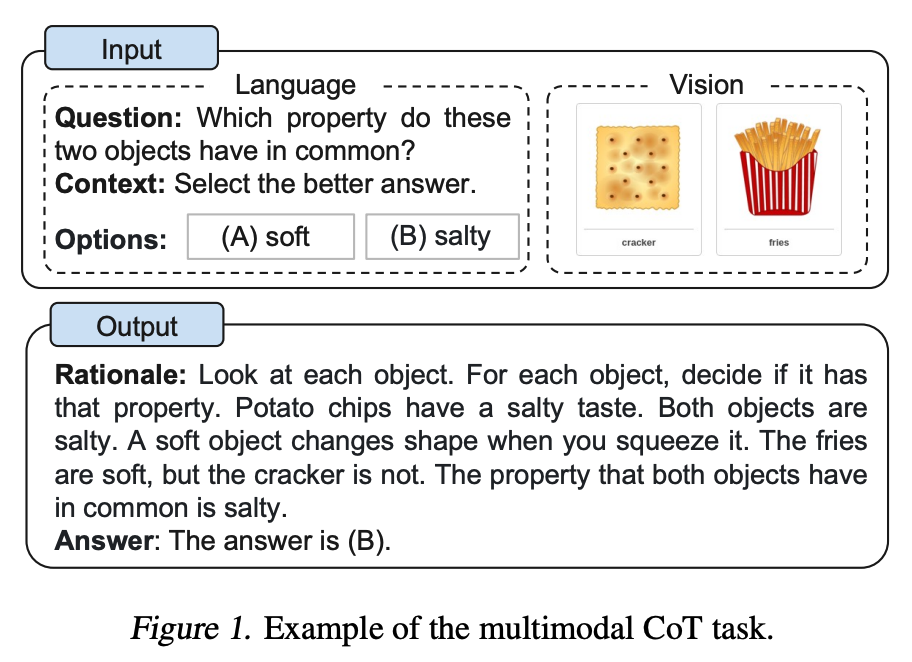
Image source: Zhang et al. (2023)
Why Multimodal CoT?
Text-only CoT hits a wall when questions involve visual information. For example:
- Science questions: Experiment diagrams, circuit diagrams, chemical structures
- Math geometry: Reading angles, lengths, and spatial relationships from figures
- Data analysis: Interpreting charts, bar graphs, line graphs
- Everyday reasoning: Observing details in photos to answer questions
In these scenarios, text descriptions alone don't provide enough information. The model needs to "see" the image to reason correctly.
Two-Stage Framework
Stage 1: Rationale Generation
The model receives both text and image as input, then generates a reasoning process (rationale). The goal: get the model to "verbalize" its thinking, including what it observes in the image and how it combines visual and textual information.
Input:
- Text: An object slides down an inclined plane at the angle shown.
The object's mass is 2kg. Find the gravitational component
along the plane.
- Image: [A diagram showing a 30-degree incline]
Rationale output:
From the diagram, the incline angle is 30 degrees. Object mass m=2kg,
gravity G = mg = 2 × 9.8 = 19.6N.
Gravitational component along the plane = G × sin(30°) = 19.6 × 0.5 = 9.8N.
Stage 2: Answer Inference
The rationale from stage 1 is concatenated with the original input (text + image) and fed to the model to generate the final answer. The two-stage approach works because the rationale acts as a "bridge," helping the model better leverage multimodal information.
Input:
- Original text + image
- Rationale (from stage 1)
Output:
Answer: The gravitational component along the plane is 9.8N
Key Technical Details
Visual Feature Fusion
Multimodal CoT uses a Vision Transformer (ViT) to extract image features, fusing them with language features through:
- Feature concatenation: Concatenate visual feature vectors with text embeddings
- Cross-attention: Let text tokens "attend to" image patches in Transformer layers
- Gating mechanism: Dynamically control the proportion of visual information injected
Hallucination Problem and Solution
The paper found something interesting: when the model uses only text input, the generated rationales frequently contain hallucinations -- fabricating information that doesn't exist in the image. Adding the visual modality significantly reduced the hallucination rate.
❌ Text-only CoT (hallucination):
"From the diagram we can see this is an equilateral triangle..."
(The actual diagram shows a right triangle)
✅ Multimodal CoT (correct):
"The diagram shows a right triangle, with one angle at 90 degrees and another labeled as 30 degrees..."
Experimental Results
Performance on ScienceQA benchmark:
| Model | Parameters | Accuracy |
|---|---|---|
| GPT-3.5 (CoT) | 175B | 75.17% |
| GPT-4 (CoT) | - | 83.99% |
| Multimodal CoT (small model) | 1B | 84.91% |
Key findings:
- A 1B-parameter multimodal CoT model beat GPT-3.5 (175B) and even slightly outperformed GPT-4
- The two-stage approach is 16% more accurate than single-stage (directly generating answers)
- Visual features are critical for reducing hallucinations -- without visual input, the hallucination rate in rationales hit 65%
Practical Applications
1. Education and Exam Assistance
Multimodal CoT is perfect for exam questions with charts and diagrams:
Prompt:
Look at the chart below and answer the question. First describe what
you see in the chart, then reason step by step to reach your answer.
[Attached image: Company revenue bar chart 2020-2025]
Question: Which year had the highest revenue growth rate?
2. Medical Imaging Analysis
Prompt:
Please analyze the following X-ray. First describe the key features
you observe in the image, then give your preliminary assessment
and reasoning process based on those observations.
[Attached image: Chest X-ray]
3. Code + Screenshot Debugging
Prompt:
Here's some code and its runtime screenshot. First describe the error
shown in the screenshot, then analyze what in the code might cause it,
and finally suggest a fix.
Code: [code block]
Screenshot: [error screenshot]
Applying This with Modern Multimodal Models
While the original paper fine-tuned a small model, the multimodal CoT concept works equally well with modern large models (GPT-4o, Claude, Gemini). You can guide the model through similar two-stage reasoning via prompting:
Please answer the question following these steps:
Step 1 (Observe and Reason):
- Carefully observe all relevant information in the image
- List key visual elements (numbers, labels, relationships)
- Describe your reasoning process
Step 2 (Arrive at Answer):
- Based on your reasoning, give the final answer
- State your confidence level and any uncertainties
Self-Check Checklist
- Does the question involve information that requires visual understanding? (If text alone suffices, use standard CoT)
- Did you explicitly ask the model to "describe observations" before "reasoning toward an answer" (two-stage thinking)?
- Is the image resolution high enough for the model to identify key details?
- Did you provide a structured output format requirement?
References
- Multimodal Chain-of-Thought Reasoning in Language Models (Zhang et al., 2023)
- Language Is Not All You Need: Aligning Perception with Language Models (2023)
- Visual Instruction Tuning (Liu et al., 2023 - LLaVA)
- GPT-4V(ision) System Card
📚 相关资源
❓ 常见问题
关于本章主题最常被搜索的问题,点击展开答案
Multimodal CoT 是什么?跟普通 CoT 有什么区别?
Zhang 等人 2023 提出,把文本和视觉融入两阶段 CoT 框架。阶段一基于多模态信息生成 rationale(推理过程),阶段二用 rationale + 原始输入推断最终答案。普通 CoT 只看文本,遇到含图的物理题、几何题、图表题就抓瞎;Multimodal CoT 强迫模型先「描述图」再「推理」,幻觉率显著下降。
1B 参数的 Multimodal CoT 能打过 GPT-3.5 吗?
ScienceQA 上确实能。论文报告:GPT-3.5(CoT)75.17%,GPT-4(CoT)83.99%,Multimodal CoT(1B 小模型)84.91%——1B 居然略胜 GPT-4 的 175B。原因是科学题大量带图,文本 LLM 看不到图必须靠 hallucination,而专门做视觉融合的小模型反而占优。
Multimodal CoT 的两阶段为什么比一阶段强?
论文实验显示两阶段比直接生成答案准确率高 16%。原因:rationale 充当「桥梁」,强制模型先把视觉信息文字化(写出从图里看到了什么),再用这个文字化结果做答案推断。一阶段直接生成答案时,视觉特征容易被语言模态盖过去;分两步后视觉信息被显式地引入推理链。
幻觉问题在 Multimodal CoT 里有改善吗?
改善明显。论文发现纯文本 CoT 生成的 rationale 中约 65% 的幻觉率——会编造图里不存在的内容(如把直角三角形说成等边三角形)。加入视觉模态后幻觉率显著下降,因为模型不再凭空想象图的内容,而是用 ViT 提取的特征作为锚点。
在 GPT-4V / Claude / Gemini 上怎么用 Multimodal CoT?
原论文是微调 1B 小模型,但思路在大模型上一样有效。Prompt 模板:第一步「仔细观察图像、列出所有视觉元素(数字、标签、关系)、描述推理过程」;第二步「基于上述推理给出最终答案 + 不确定性说明」。强制两阶段就能复现论文里观察到的幻觉率下降。