Basics
Core concepts of prompting LLMs, including zero-shot and few-shot prompting
Prompting LLMs
You can get a lot of results with simple prompts, but the quality scales with how much information you provide and how well-crafted it is. A prompt can contain instructions, questions, context, input data, or examples — all of which help steer the model toward better results.
Here's a simple example:
Prompt:
The sky is
Output:
blue.
If you're using the OpenAI Playground or any other LLM Playground, you can prompt the model as shown in the screenshot below:
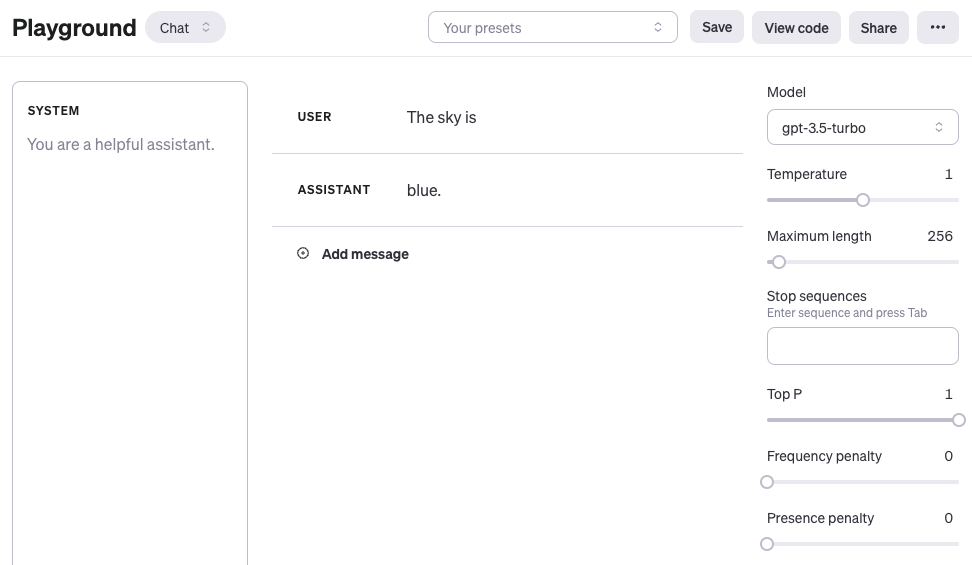
One thing to note: when using OpenAI's chat models like gpt-4 or gpt-3.5-turbo, you can structure prompts with three different roles: system, user, and assistant. The system role isn't required, but it helps set the overall behavior of the assistant — think of it as telling the model who it is and how it should respond. The example above only uses a user message, which works fine as a direct prompt. For simplicity, all examples in this chapter (unless explicitly stated) will just use user messages with the gpt-3.5-turbo model. The assistant message in the example above is the model's response. You can also define assistant messages to show the model examples of desired behavior. More on using chat models here: https://www.promptingguide.ai/models/chatgpt
The takeaway from that example: the language model completed the text based on the context "The sky is". The output might surprise you or miss the mark entirely. And that's the point — it highlights why you need more context or clearer instructions about what you actually want. That's what prompt engineering is all about.
Let's improve it:
Prompt:
Complete the sentence:
The sky is
Output:
blue during the day and dark at night.
Better, right? We told the model to complete the sentence, so the output makes more sense — it did exactly what we asked ("complete the sentence").
These examples show what today's LLMs can do at a basic level. They handle all sorts of advanced tasks: text summarization, math reasoning, code generation, and more.
Model settings
If you notice the same prompt giving wildly different outputs each time, check your model settings first (like temperature / top_p). Start with the next chapter:
Prompt formats
The examples above used pretty simple prompts. A standard prompt usually follows one of these formats:
<question>?
Or:
<instruction>
You can also use Q&A format (standard in many Q&A datasets):
Q: <question>?
A:
When you prompt like this without providing examples, it's called zero-shot prompting — you're asking the model to respond without any demonstrations of the task. Some LLMs can handle zero-shot prompting well, but it depends on task complexity, knowledge coverage, and how the model was aligned during training.
A zero-shot prompt example:
Prompt:
Q: What is prompt engineering?
With newer models, you can skip the "Q:" part entirely — the model figures out it's a Q&A task from context. So the prompt simplifies to:
Prompt:
What is prompt engineering?
Building on these standard formats, there's a popular and effective technique called few-shot prompting, where you provide examples (demonstrations). Here's the format:
<question>?
<answer>
<question>?
<answer>
<question>?
<answer>
<question>?
Q&A version:
Q: <question>?
A: <answer>
Q: <question>?
A: <answer>
Q: <question>?
A: <answer>
Q: <question>?
A:
Whether you use Q&A format depends on the task type. For instance, you can do a simple classification task with examples like this:
Prompt:
This is awesome! // Positive
This is bad! // Negative
Wow that movie was rad! // Positive
What a horrible show! //
Output:
Negative
LLMs can pick up tasks from just a few examples, and few-shot prompting enables this in-context learning ability. We'll cover zero-shot and few-shot prompting more extensively in later chapters.
Turn this chapter's knowledge into practical skills
Enter the interactive lab and practice Prompt with real tasks. Get started in 10 minutes.
📚 相关资源
❓ 常见问题
关于本章主题最常被搜索的问题,点击展开答案
OpenAI chat 模型里 system / user / assistant 三个 role 各干什么?
用 gpt-4 或 gpt-3.5-turbo 时:system 设定整体行为(不必填,但定身份很有用),user 是真正的提问,assistant 是模型回复。也可以预填 assistant message 当作示范。本章绝大多数示例只用 user message 跑 gpt-3.5-turbo,足够覆盖基础场景。
为什么「The sky is」输出 blue,而「Complete the sentence: The sky is」输出更长?
前者只给 LLM 一段未完成文本,模型按概率续写最短合理 token——blue。后者多了显式指令「Complete the sentence」,模型识别这是补全任务,输出 blue during the day and dark at night。差别就是有没有告诉它「要做什么」。
同一个 Prompt 每次输出差异巨大,先调 Prompt 还是先调参数?
先查 model settings——重点是 temperature 和 top_p。Prompt 没问题但输出不稳定,几乎都是采样参数没控住。把 temperature 设到 0、top_p 留 1.0,再决定要不要改 prompt 措辞,否则会把参数问题误判为指令问题。
标准 Prompt 格式有哪些写法?
三种基础写法:直接问句 `<question>?`、纯指令 `<instruction>`、Q&A 模板 `Q: <question>?\nA:`。新模型已经能从语境推断出 Q&A 任务,所以「Q:/A:」可以省略;老模型或要严格控格式时再加上。
Zero-shot 和 Few-shot 在 prompt 写法上差别多大?
Zero-shot 直接发问不给示例(如 `What is prompt engineering?`);Few-shot 在问之前堆 1-N 个示范对,例如 `This is awesome! // Positive` 接 `This is bad! // Negative`,最后留一行空让模型分类。Few-shot 触发的就是 in-context learning——靠例子对齐输出风格和标签。