RAG
Retrieval-Augmented Generation: improve factuality with retrieval
General-purpose language models can handle common tasks like sentiment analysis and named entity recognition with fine-tuning. These tasks don't need extra background knowledge.
But for more complex, knowledge-intensive tasks, you can build a system on top of a language model that accesses external knowledge sources. This makes outputs more factually consistent, more reliable, and helps reduce hallucinations.
Meta AI researchers introduced Retrieval Augmented Generation (RAG) for exactly these kinds of tasks. RAG combines an information retrieval component with a text generation model. It can be fine-tuned, and its internal knowledge can be updated efficiently without retraining the whole model.
RAG takes an input, retrieves a set of relevant/supporting documents (from a source like Wikipedia), and combines those documents as context with the original prompt before feeding everything to the text generator. This makes RAG much better at handling facts that change over time. And that matters -- LLM parametric knowledge is static. RAG lets the model access the latest information without retraining, producing reliable outputs based on retrieval.
Lewis et al. (2021) proposed a general RAG fine-tuning recipe. It uses a pre-trained seq2seq model as parametric memory and a dense vector index of Wikipedia as non-parametric memory (accessed via a neural pre-trained retriever). Here's how it works:
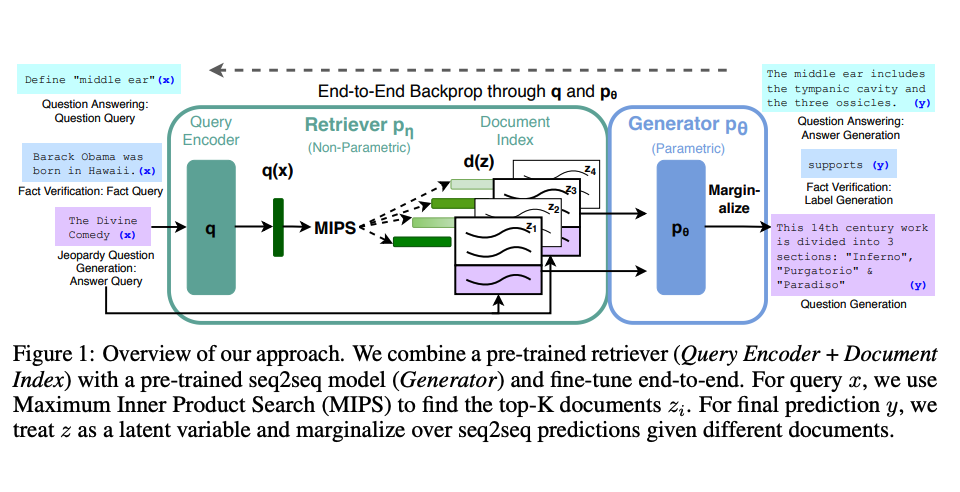
Image source: Lewis et al. (2021)
RAG performed strongly on benchmarks like Natural Questions, WebQuestions, and CuratedTrec. On MS-MARCO and Jeopardy questions, RAG generated answers that were more factual, more specific, and more diverse. FEVER fact verification also improved with RAG.
This shows RAG is a viable approach for boosting language model output on knowledge-intensive tasks.
Recently, retriever-based methods have become increasingly popular, often combined with popular LLMs like ChatGPT to improve their capabilities and factual consistency.
You can find a simple example of using a retriever and LLM for question answering with source citations in the LangChain docs.
📚 相关资源
❓ 常见问题
关于本章主题最常被搜索的问题,点击展开答案
RAG 是 Meta AI 提出的,它具体解决什么问题?
RAG(Retrieval Augmented Generation,Lewis 等人 2021)把信息检索组件和文本生成模型拼在一起,专门治知识密集型任务。模型输入时先去外部知识源(如维基百科)检索相关文档,再连同 prompt 一起喂给生成器。好处:缓解幻觉、答案带来源、知识更新不用重训整个模型。
RAG 和 fine-tuning 怎么选?
事实会变、知识库经常更新(产品文档、法规、wiki)选 RAG——改向量库就行,不动模型。要让模型学风格、领域语气、固定输出格式选 fine-tuning。两者也能叠:fine-tune 调风格 + RAG 注入实时事实,是企业知识问答最常见的组合。
Lewis 2021 的 RAG 在哪些 benchmark 上有效?
论文报告 RAG 在 Natural Questions、WebQuestions、CuratedTrec 上表现抢眼,在 MS-MARCO 和 Jeopardy 上生成的答案更符合事实、更具体、更多样,在 FEVER 事实验证上也得到更好结果。证明 RAG 在「问答 + 事实验证」这类知识密集型任务里是站得住脚的。
RAG 用什么做检索器和生成器?
Lewis 2021 的通用配方:预训练 seq2seq 模型作为参数化记忆(生成器),维基百科的密集向量索引作为非参数化记忆(被神经网络预训练过的检索器访问)。现代实现里 retriever 通常是 dense embedding(如 OpenAI / BGE),generator 用 GPT-4 / Claude,向量库放 Pinecone / Weaviate / pgvector。
ChatGPT 已经很强了,还有必要用 RAG 吗?
需要。LLM 的参数化知识是静态的——训练截止后发生的事、内部文档、最近的合同/政策,模型都不知道。RAG 让 LLM 不重训就能拿到最新信息,而且答案附来源便于审计。所以基于 retriever 的方法越来越流行,常和 ChatGPT 这种 LLM 配合提升事实一致性。