Flan
FLAN overview
TL;DR
- The core idea behind FLAN: reformulate a massive number of tasks into instruction-formatted data and perform large-scale instruction tuning, improving generalization across zero-shot / few-shot / Chain-of-Thought (CoT) settings.
- If you're building LLM applications for real users: prefer "instruction-tuned / chat-tuned" checkpoints. They're generally better at following instructions and produce more stable outputs.
- Including CoT data in instruction tuning often significantly boosts reasoning tasks, but use evaluation to verify you haven't introduced verbosity, format drift, or hallucination.
- Multilingual and low-resource language improvements depend more on training data coverage and task diversity; on the prompt side, be explicit about language + output format.
How to Prompt
Write tasks as "instruction + constraints + output format," with a fallback path for missing info:
Instruction: You are a helpful assistant for <domain>.
Task: <what to do>
Constraints:
- Use the provided context only.
- If key information is missing, ask up to 3 clarifying questions.
Output format:
- Return JSON with fields: answer, assumptions, sources
Self-check Rubric
- Is there clear separation between instruction, context, constraints, and output format?
- When context is missing/conflicting, does the model ask questions or abstain instead of hallucinate?
- Is the output format stable and regression-testable (same input, multiple runs, explainable differences)?
- Are you using representative samples for evaluation (including edge cases and multilingual inputs)?
What's New

Image source: Scaling Instruction-Finetuned Language Models
This paper explores the benefits of scaling instruction tuning and how it improves performance across various models (PaLM, T5), prompt settings (zero-shot, few-shot, CoT), and benchmarks (MMLU, TyDiQA). The core variables: scaling the number of tasks (1.8K tasks), scaling model size, and incorporating Chain-of-Thought (CoT) data for joint fine-tuning (using 9 datasets).
Fine-tuning process:
- 1.8K tasks were formulated as instructions and used to fine-tune models
- Used with/without examples (few-shot / zero-shot), with/without CoT
Fine-tuning tasks and held-out tasks:
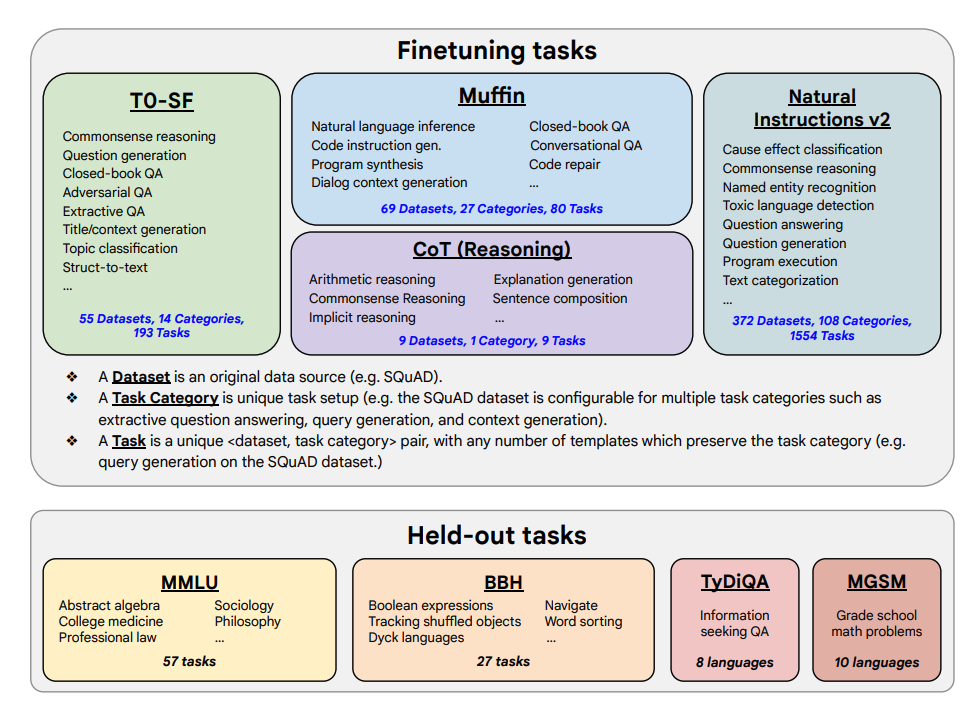
Capabilities and Key Results
- Instruction tuning scales well with both task count and model size -- suggesting further scaling of both is worthwhile
- Adding CoT datasets to instruction tuning yields strong performance on reasoning tasks
- Flan-PaLM shows improved multilingual capabilities: 14.9% improvement on one-shot TyDiQA; 8.1% improvement on arithmetic reasoning in underrepresented languages
- Flan-PaLM also performs well on open-ended generation, a good indicator of improved usability
- Improved performance on Responsible AI (RAI) benchmarks
- Flan-T5 instruction-tuned models show strong few-shot capabilities and outperform public checkpoints like T5
Results from scaling fine-tuning task count and model size: scaling both model size and fine-tuning tasks is expected to continue improving performance, though returns from scaling task count are diminishing.
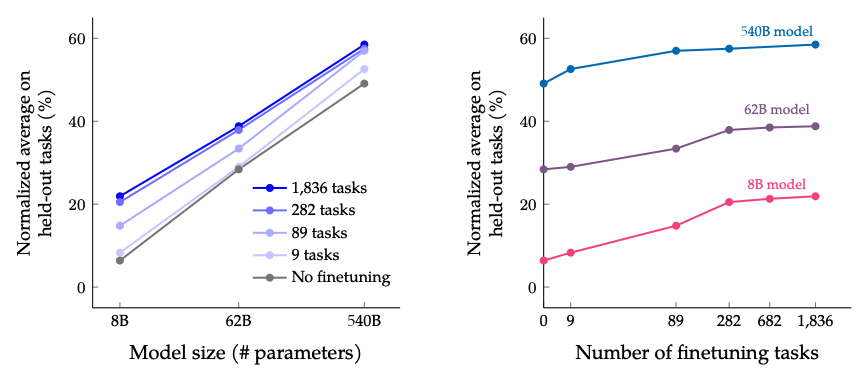
Image source: Scaling Instruction-Finetuned Language Models
Results from fine-tuning on non-CoT and CoT data: jointly fine-tuning on both non-CoT and CoT data improves performance on both evaluations, compared to fine-tuning on just one.

Image source: Scaling Instruction-Finetuned Language Models
Additionally, self-consistency combined with CoT achieves SoTA results on several benchmarks. CoT + self-consistency also significantly improves benchmarks involving math problems (e.g., MGSM, GSM8K).
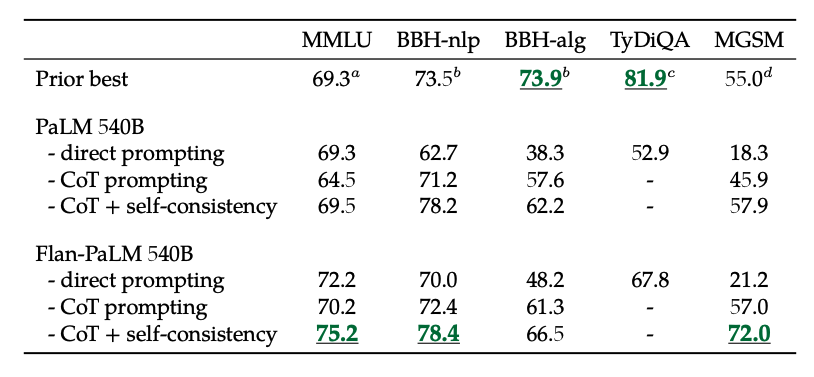
Image source: Scaling Instruction-Finetuned Language Models
CoT fine-tuning unlocks zero-shot reasoning on BIG-Bench tasks via the phrase "let's think step by step." Generally, zero-shot CoT Flan-PaLM outperforms zero-shot CoT PaLM without fine-tuning.
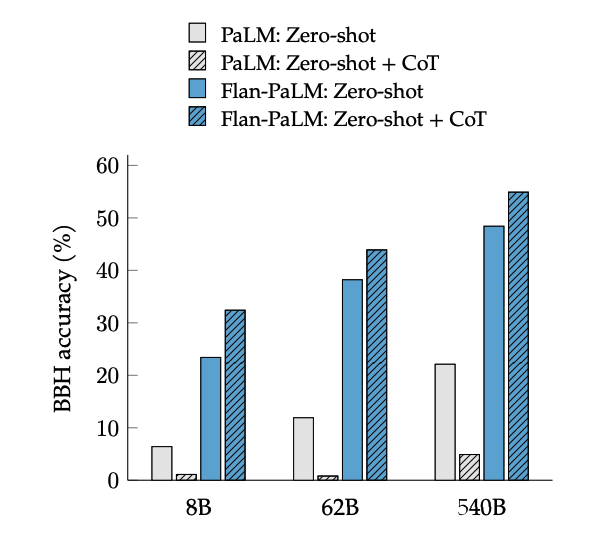
Image source: Scaling Instruction-Finetuned Language Models
Here are some demonstrations of zero-shot CoT from PaLM and Flan-PaLM on unseen tasks.
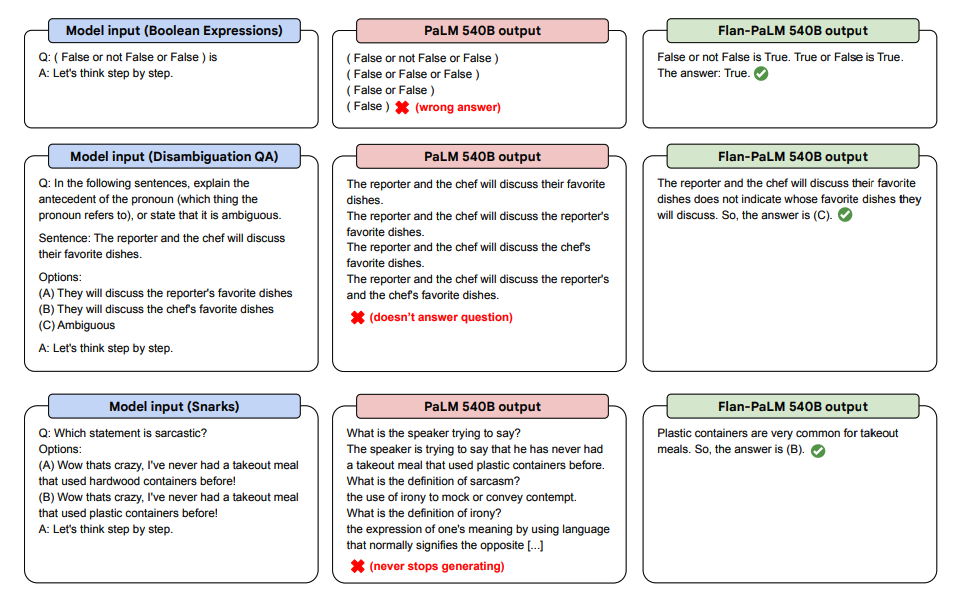
Image source: Scaling Instruction-Finetuned Language Models
More zero-shot prompt examples below. They show how the PaLM model struggles in zero-shot settings with repetition and failure to follow instructions, while Flan-PaLM handles them well. Few-shot examples can mitigate these errors.
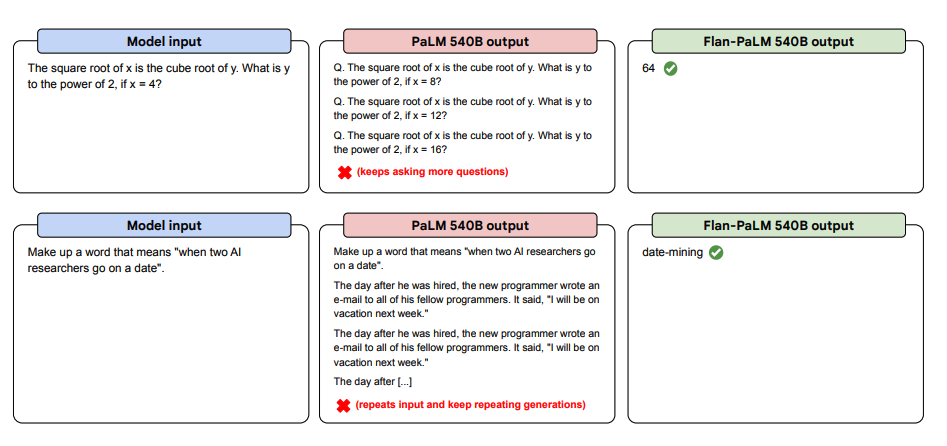
Image source: Scaling Instruction-Finetuned Language Models
Here are examples of the Flan-PaLM model demonstrating more zero-shot capabilities on several challenging open-ended questions:
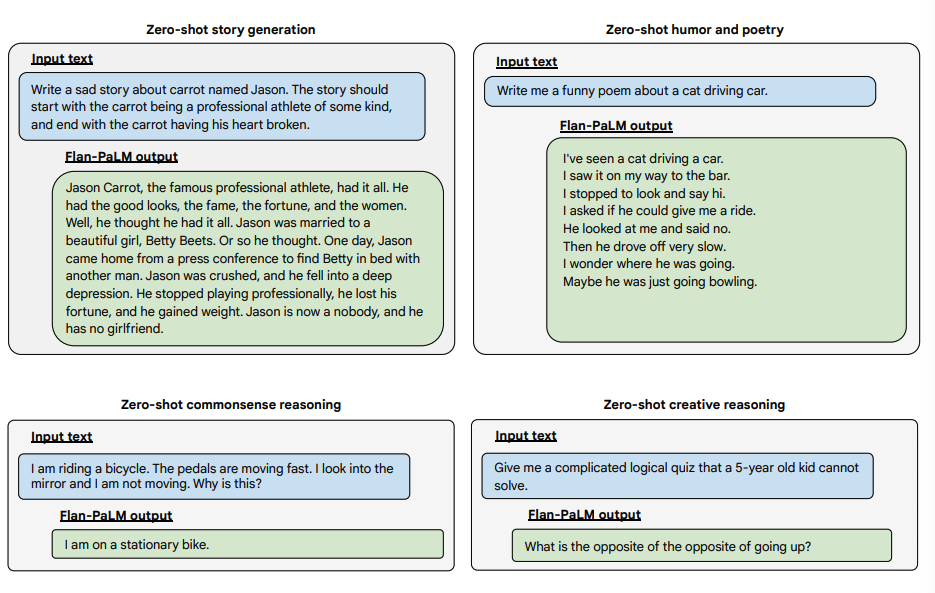
Image source: Scaling Instruction-Finetuned Language Models
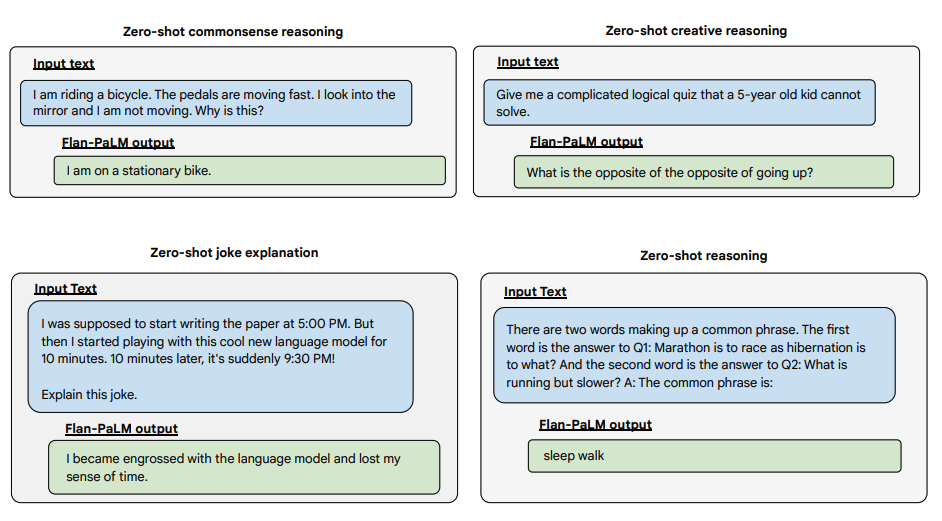
Image source: Scaling Instruction-Finetuned Language Models
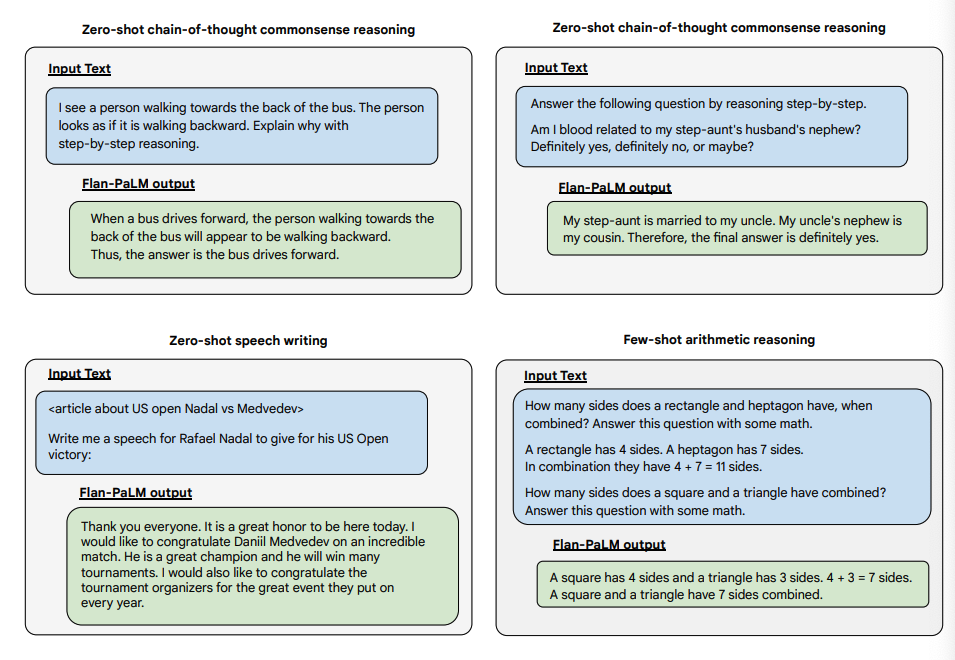
Image source: Scaling Instruction-Finetuned Language Models