Chain-of-Thought (CoT)
Improve reasoning task reliability with intermediate thinking steps
Chain-of-Thought (CoT) Prompting
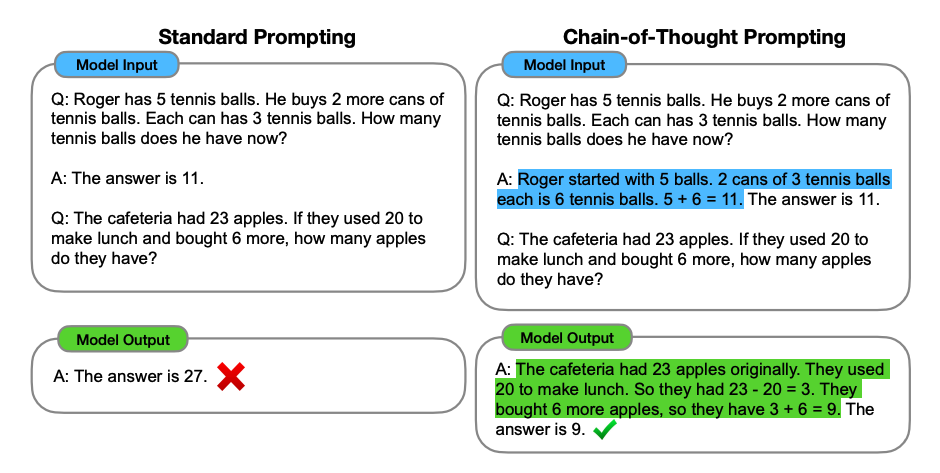
Image source: Wei et al. (2022)
Chain-of-thought (CoT) prompting, introduced in Wei et al. (2022), enables complex reasoning through intermediate steps. Combine it with few-shot prompting and you get much better results on tasks that require thinking before answering.
Prompt:
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.
The odd numbers in this group add up to an even number: 17, 10, 19, 4, 8, 12, 24.
A: Adding all the odd numbers (17, 19) gives 36. The answer is True.
The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24.
A: Adding all the odd numbers (11, 13) gives 24. The answer is True.
The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2.
A: Adding all the odd numbers (17, 9, 13) gives 39. The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:
Output:
Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False.
Perfect result once we provided reasoning steps. And here's what's cool -- you can get away with fewer examples. Even just one example is enough:
Prompt:
The odd numbers in this group add up to an even number: 4, 8, 9, 15, 12, 2, 1.
A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:
Output:
Adding all the odd numbers (15, 5, 13, 7, 1) gives 41. The answer is False.
Keep in mind that the authors claim this is an emergent ability that only appears in sufficiently large language models.
Turn this chapter's knowledge into practical skills
Enter the interactive lab and practice Prompt with real tasks. Get started in 10 minutes.
Zero-Shot CoT Prompting

Image source: Kojima et al. (2022)
Zero-shot CoT (Kojima et al., 2022) is a neat idea: just add "Let's think step by step" to your prompt. That's it. Let's see how it works on a simple problem.
Prompt:
I went to the market and bought 10 apples. I gave 2 apples to my neighbor and 2 apples to the repairman. Then I went and bought 5 more apples and ate 1. How many apples do I have left?
Output:
11 apples
Wrong. Now let's try with the magic phrase.
Prompt:
I went to the market and bought 10 apples. I gave 2 apples to my neighbor and 2 apples to the repairman. Then I went and bought 5 more apples and ate 1. How many apples do I have left?
Let's think step by step.
Output:
First, you start with 10 apples.
You gave 2 apples to your neighbor and 2 apples to the repairman, so you have 6 apples left.
Then you bought 5 more apples, so now you have 11 apples.
Finally, you ate 1 apple, so you have 10 apples left.
Pretty impressive that such a simple prompt works this well. It's especially useful when you don't have examples to include in your prompt.
Auto-CoT (Automatic Chain-of-Thought)
Crafting effective and diverse CoT examples by hand is tedious. And manual work often leads to suboptimal solutions. Zhang et al. (2022) proposed a way to eliminate the manual effort: use LLMs with "Let's think step by step" to automatically generate reasoning chains. But auto-generated chains can contain errors. So diversity matters -- that's why they proposed Auto-CoT, which samples questions with diversity and generates reasoning chains for demonstrations.
Auto-CoT has two main stages:
- Stage 1: Question Clustering -- partition the given questions into clusters
- Stage 2: Demonstration Sampling -- pick a representative question from each cluster and use Zero-Shot-CoT with simple heuristics to generate its reasoning chain
The heuristics are things like question length (e.g., 60 tokens) and number of reasoning steps (e.g., 5 steps). This encourages simple and accurate demonstrations.
Here's the process:

Image source: Zhang et al. (2022)
Auto-CoT code is available here: Github.
📚 相关资源
❓ 常见问题
关于本章主题最常被搜索的问题,点击展开答案
Chain-of-Thought 跟普通 few-shot 的区别在哪?
区别在每条 demonstration 的「答案」字段。Few-shot 只写 `A: Answer is False.`,CoT(Wei et al. 2022)会写 `A: Adding all the odd numbers (9, 15, 1) gives 25. The answer is False.`——把中间推理步骤显式塞进示范。模型会模仿这个推理过程,奇偶和那个例子一下就答对。
Zero-shot CoT 是怎么回事?只加一句话就能涨智商?
Kojima et al. 2022(arxiv 2205.11916)发现:在原 prompt 末尾加一句 `Let's think step by step.`,模型自动产生推理链。教程里 10 个苹果的算术题,原版 prompt 输出 `11 apples`(错),加了 step-by-step 后正确分解到 `10 apples left`。零示范,零工程量。
CoT 是 emergent ability,什么意思?
Wei et al. 2022 原文:CoT 只在「足够大」的语言模型上出现——小模型加推理链反而更差。具体阈值跟模型架构有关,但典型的「emergent」转折点出现在 100B 参数以上。这意味着用 small model 走 CoT 不仅没收益,可能拖累准确率。
Auto-CoT 跟普通 CoT 比省了什么?
省了人工写 demonstration 的成本。普通 CoT 需要手写多样化的有效示例,工作量大且容易选偏。Zhang et al. 2022(arxiv 2210.03493)的 Auto-CoT 两阶段:(1) 问题聚类,(2) 每簇里选代表问题,用 zero-shot CoT「Let's think step by step」自动生成推理链。启发式:60 token 长度 + 5 步推理。
什么时候用 CoT,什么时候不用?
用 CoT:算术、常识推理、符号推理、多跳问答这种需要中间步骤的任务。不用 CoT:分类、提取、翻译、总结这种 input→output 直接映射的任务——加 step-by-step 反而让输出变长、加 token 成本。CoT 让 token 数翻几倍,cost-sensitive 的高频任务要慎用。