Llama
Llama overview
TL;DR
- LLaMA is a family of foundation models from Meta (7B-65B) that achieved strong baselines at equivalent inference budgets through "more thorough data training + efficient training strategies."
- For production, you'd typically pick an instruction-tuned / chat-tuned variant. The base model is better suited for continued pretraining, domain adaptation, or as a research base.
- Prompt-wise: base models need more explicit output format, style, and constraints. For factual tasks, connect RAG and require evidence.
- Don't evaluate on a single benchmark: use your real task distribution for evaluation, paying attention to robustness (long context, noise, format, language mixing).
How to Prompt
For base models, prioritize templates with "explicit rules + explicit format + explicit abstain strategy":
You are a helpful assistant for <domain>.
Rules:
- Follow the output format exactly.
- If information is missing, ask clarifying questions.
- If you are not confident, say "Unsure" and explain why.
Task:
<task description>
Output format:
<schema or bullet list>
Self-check Rubric
- Have you distinguished between base model vs instruction-tuned expectations (follow instructions / verbosity / safety)?
- Is the format constraint written as a verifiable schema (not just a verbal description)?
- Have you added evidence/abstain strategies for hallucination risk?
- Are you using representative samples for evaluation, recording prompt/model versions for regression?
What's New
This paper introduces a set of foundation models ranging from 7B to 65B parameters.
These models were trained on trillions of tokens from publicly available datasets.
The work by (Hoffman et al. 2022) showed that smaller models trained on more data can achieve better performance than larger models under smaller compute budgets. The paper recommended training a 10B model on 200B tokens. But the LLaMA paper found that a 7B model's performance keeps improving even past 1T tokens.
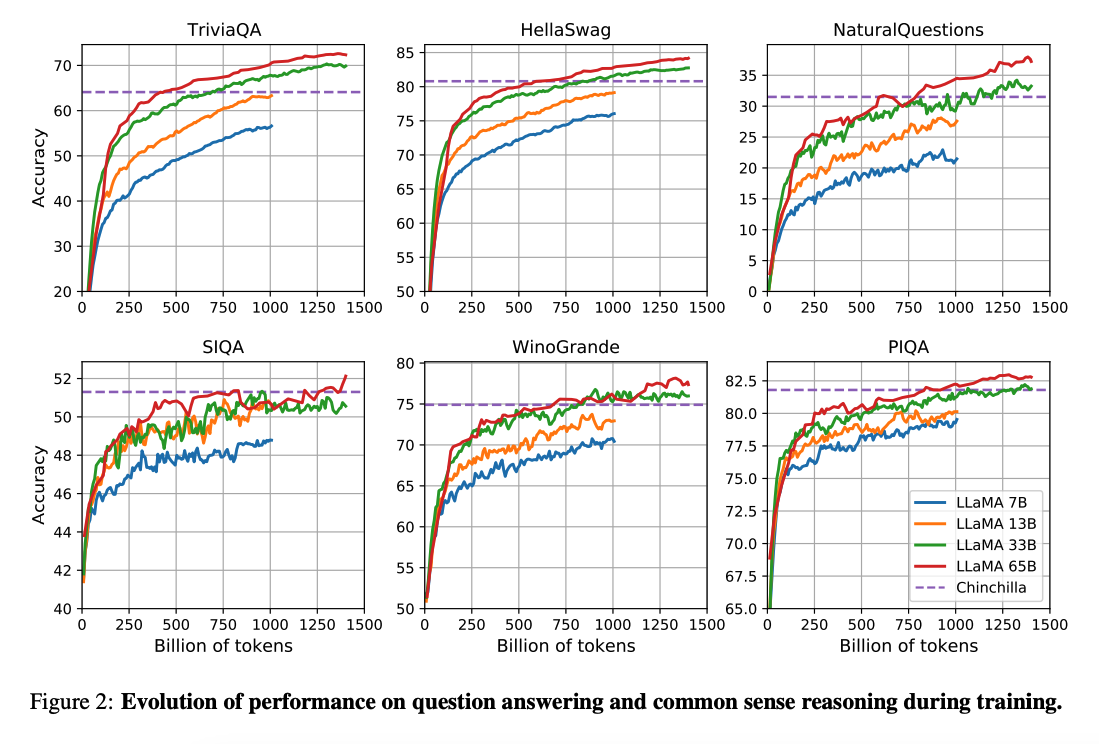
This work focuses on training models (LLaMA) with more tokens to achieve the best possible performance at various inference budgets.
Capabilities and Key Results
Overall, despite being 10x smaller than GPT-3 (175B), LLaMA-13B outperforms GPT-3 on many benchmarks and can run on a single GPU. LLaMA 65B is competitive with models like Chinchilla-70B and PaLM-540B.
Paper: LLaMA: Open and Efficient Foundation Language Models
Code: https://github.com/facebookresearch/llama
References
- Koala: A Dialogue Model for Academic Research (April 2023)
- Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data (April 2023)
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality (March 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention (March 2023)
- GPT4All (March 2023)
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge (March 2023)
- Stanford Alpaca (March 2023)