ToT
Tree of Thoughts: explore the solution space via search
For complex tasks that require exploration or strategic lookahead, traditional prompting techniques don't cut it. Yao et al. (2023) proposed the Tree of Thoughts (ToT) framework, which builds on chain-of-thought prompting and guides language models to explore thoughts as intermediate steps for general problem solving.
ToT maintains a tree of thoughts, where thoughts are coherent language sequences that serve as intermediate steps toward solving a problem. This lets the LM evaluate its own intermediate thoughts during rigorous reasoning. It combines the ability to generate and evaluate thoughts with search algorithms (BFS, DFS) to systematically explore while validating forward and backtracking.
Here's how the ToT framework works:
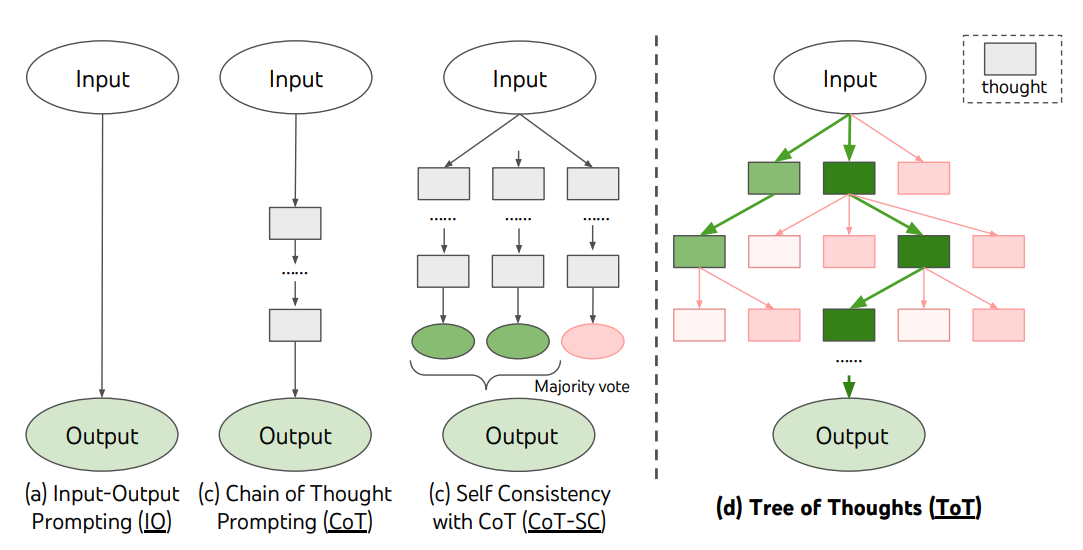
Image source: Yao et al. (2023)
ToT requires defining the number of thoughts/steps and the number of candidates per step, depending on the task. For example, the "Game of 24" in the paper is a math reasoning task that needs 3 thought steps, each requiring an intermediate equation. Each step keeps the top 5 candidates.
For the Game of 24, ToT uses breadth-first search (BFS), where the LM evaluates each thought candidate as "sure/maybe/impossible." The authors explain: "the aim is to promote correct partial solutions that can be verified as sure with few lookahead trials, eliminate impossible partial solutions based on 'too big/too small' commonsense, and keep the rest as maybe." Each step samples 3 evaluations. The process looks like this:
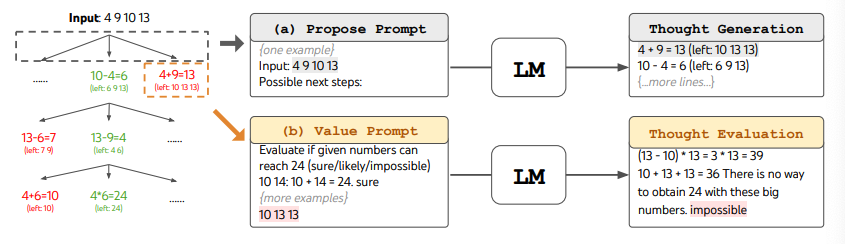
Image source: Yao et al. (2023)
The results speak for themselves -- ToT significantly outperforms other prompting methods:
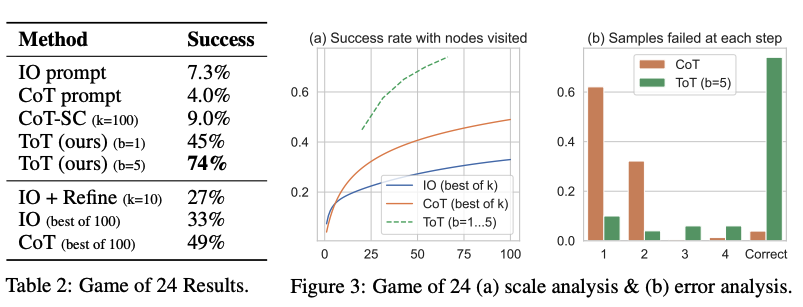
Image source: Yao et al. (2023)
Code examples can be found here and here.
Big picture: Yao et al. (2023) and Long (2023) share a similar core idea -- both enhance LLM problem-solving through multi-turn conversation in a tree search format. The main difference is that Yao et al. (2023) uses DFS/BFS/beam search, while Long (2023) proposes a "ToT Controller" trained via reinforcement learning to drive the search strategy (including when to backtrack and how far). DFS/BFS/beam search are generic -- they don't adapt to specific problems. A RL-trained ToT Controller, on the other hand, can learn from new datasets or through self-play (think AlphaGo vs. brute force search). So even with a frozen LLM, an RL-based ToT system can keep evolving and learning.
Hulbert (2023) distilled the main ToT concepts into a short prompt that guides the LLM to evaluate intermediate thoughts in a single prompt. Here's an example:
Imagine three different experts are answering this question.
Each expert writes down the first step of their thinking, then shares it.
Then each expert writes down the next step of their thinking and shares it.
Continue until all experts have completed all their steps.
If any expert makes a mistake, remove that expert from the discussion.
Question: ...
📚 相关资源
❓ 常见问题
关于本章主题最常被搜索的问题,点击展开答案
Tree of Thoughts 和 CoT 区别是什么?
CoT 是一条线性推理链,错了就错到底;ToT(Yao 等人 2023)维护一棵思维树,每个节点都是中间步骤,LM 自己评估每个分支的好坏,再用 BFS / DFS / beam search 探索,可以前进也可以回溯。复杂推理任务(如算 24 游戏)这种允许试错的场景,ToT 大幅优于 CoT。
ToT 的「算 24 游戏」具体怎么跑?
论文把任务拆成 3 个思维步骤,每步生成一个中间方程;每步保留最优 5 个候选,BFS 探索。每个候选要求 LM 评估能否得到 24,输出 sure / maybe / impossible。基于「太大/太小」的常识剪掉 impossible,sure 优先尝试,maybe 留作备选。整体比 CoT 准确率高很多。
ToT 什么时候比 CoT 强?什么时候不值得用?
需要探索多条路径、允许回溯的复杂推理任务(数学拼图、规划、写作大纲生成)选 ToT。简单算术、信息抽取、单步推理用 CoT 就够了——ToT 一次要展开 N 倍候选 × M 步评估,token 成本和延迟都是 CoT 的几倍到几十倍,跑大批量任务前先掂量。
Hulbert 提出的 ToT 提示法是什么?
Hulbert (2023) 把 ToT 框架压成一段 prompt:让模型扮演 3 个专家,每人写下推理第一步并分享,然后写下下一步……如果有人犯错就把他从讨论中移除。这相当于在一次提示里做轻量级 ToT,不需要专门的搜索代码,适合普通 ChatGPT 用户。
Yao 2023 和 Long 2023 两版 ToT 有什么不一样?
核心思路一样——多轮对话搜索树解决复杂问题。区别在搜索策略:Yao 2023 用通用的 DFS / BFS / beam search;Long 2023 提出由强化学习训练的「ToT 控制器」驱动搜索,决定什么时候回退、回退到哪一级。控制器可以从新数据或自对弈中学习,所以即使 LLM 冻结,ToT 系统仍能不断进化。