Phi-2
Phi-2 overview
TL;DR
- Phi-2 is a representative of the small language model (SLM) approach: focused on reasoning/language understanding capabilities and deployment feasibility at a smaller parameter scale.
- Good for: cost-sensitive scenarios, lightweight reasoning, basic coding assistance. Complex tasks need a stronger model or stricter prompt constraints.
- Production advice: lock down the prompt template and output format, run small-scale evaluation for regression, and avoid "looks smart but occasionally wrong."
How to Prompt
Instruct: <your instruction>
Constraints:
- Keep the output concise.
- If unsure, say "Unsure".
Output:
Self-check Rubric
- Does the output follow the template (no extra paragraphs, no format drift)?
- Can it abstain when uncertain (output Unsure)?
- Does it stay consistent on arithmetic/logic tasks across multiple runs?
This guide covers Phi-2 (a 2.7 billion parameter language model), how to prompt it effectively, and its capabilities. It also includes tips, applications, limitations, key references, and additional reading.
Phi-2 Introduction
Phi-2 is the latest small language model (SLM) released by Microsoft Research. Phi-2 builds on the previous Phi-1 and Phi-1.5 models.
Phi-1 is a 1.3B parameter model trained on "textbook quality" web data (6B tokens) plus synthetically generated textbooks and exercises using GPT-3.5 (1B tokens) (Gunasekar et al. 2023). Phi-1 excels at Python code generation tasks.
Phi-1.5 improved on the previous model, focusing on common sense reasoning and language understanding. Phi-1.5 can perform complex reasoning tasks like elementary math and basic coding, matching models roughly 5x its size.
Phi-2 is a 2.7B parameter model with improved reasoning and language understanding. It outperforms models roughly 25x its size and now has an MIT license, making it available for commercial use.
Understanding and Evaluating Phi-2
LLM researchers are keen to explore whether small language models have capabilities similar to larger models, and whether specific training techniques can help achieve this.
The model is trained on "textbook quality" data (1.4 trillion tokens with multiple passes), including synthetic datasets that help the model learn common sense reasoning and general knowledge, augmented with educational and high-quality web content. Phi-2 was trained on 96 A100 GPUs for 14 days. No additional RLHF or instruction tuning was applied.
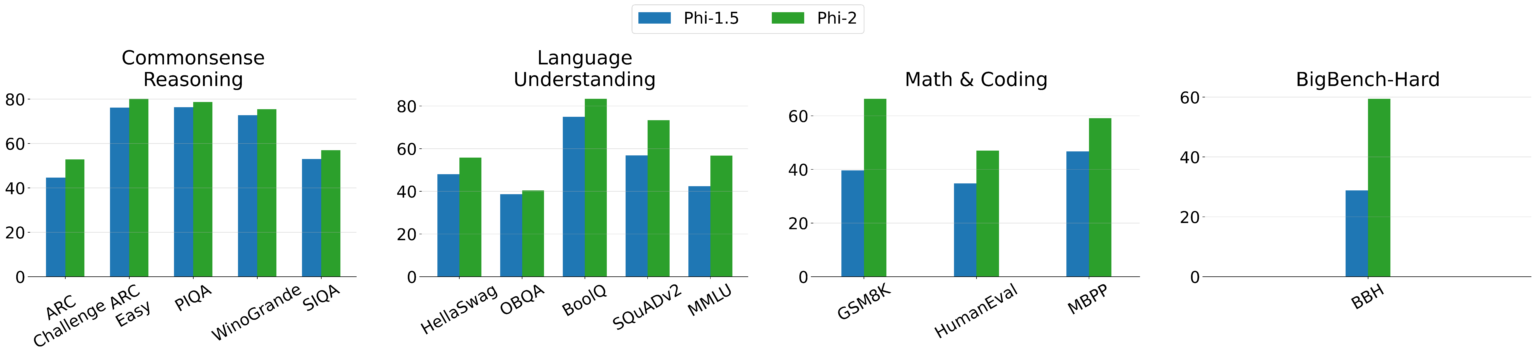
Knowledge from Phi-1.5 was transferred to Phi-2, which helped with convergence and performance across multiple benchmarks. The figure below compares Phi-2 (2.7B) and Phi-1.5 (1.3B) on common sense reasoning, math reasoning, code generation, and other language understanding benchmarks. Note that all tasks are evaluated using 0-shot, except BBH and MMLU which use 3-shot CoT and 5-shot respectively.
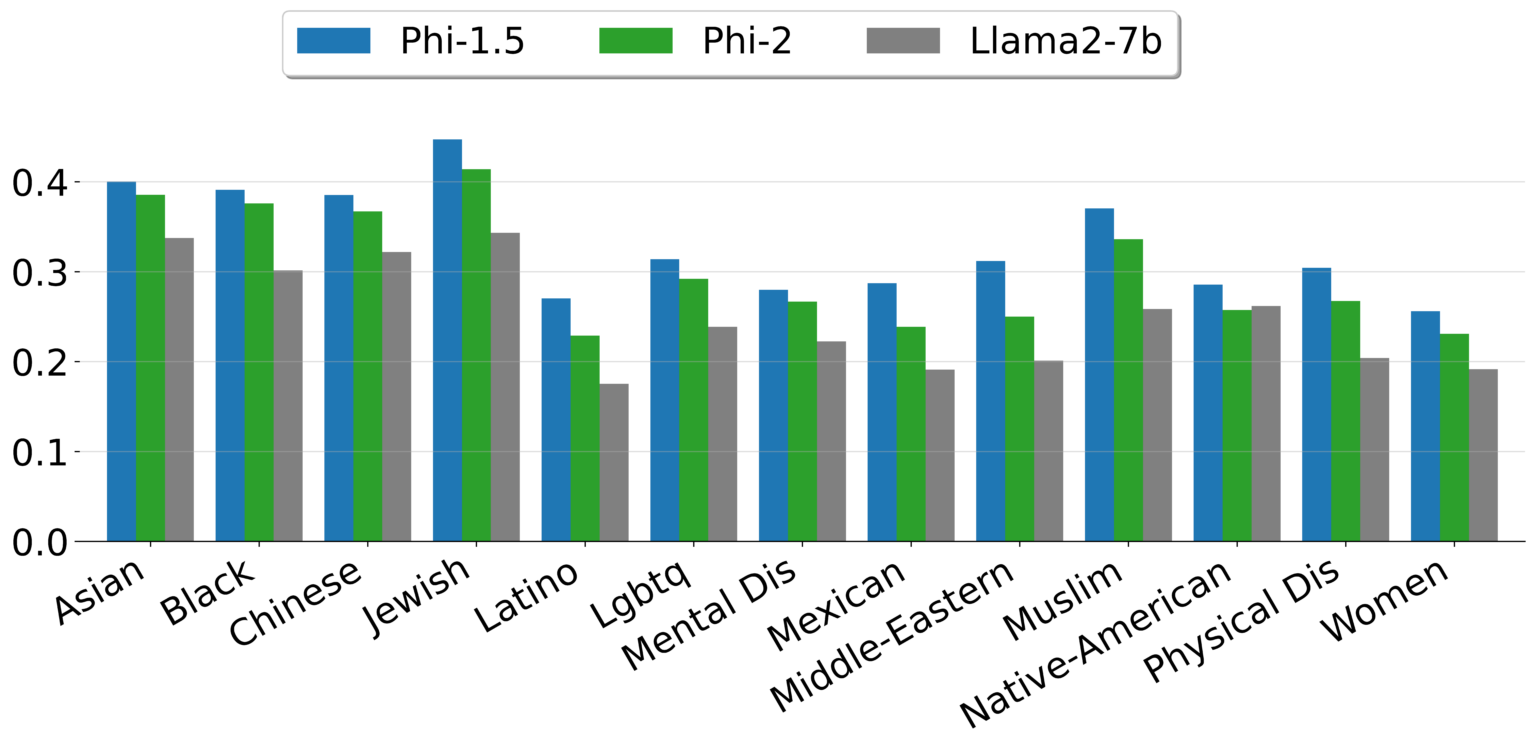
While the model doesn't use special techniques like RLHF, it's reportedly safer in terms of harmfulness and bias compared to the open-source Llama2-7b -- the authors attribute this to data curation efforts.
As shown below, Phi-2 outperforms Mistral 7B and Llama 2 (13B) on various benchmarks. Phi-2 even surpasses the Llama-2-70B model on multi-step reasoning tasks. Phi-2 also outperforms Google's Gemini Nano 2.

Below are several prompt examples demonstrating Phi-2's capabilities across different tasks.
Solving Physics Problems with Phi-2
This example demonstrates Phi-2's ability to solve physics problems:

Finding Student Mistakes with Phi-2
This example demonstrates Phi-2's ability to identify calculation errors in a student's physics problem solution:

Using Phi-2
According to the model page, Phi-2 can be prompted using QA format, chat format, and code format. Here are demonstrations across different scenarios:
QA Format
QA format is useful when you want to ask the model a question and get a concise answer.
You can use this prompt template:
Instruct: {{prompt}}
Output:
Here's an example:
Prompt:
Instruct: What's the difference between data and information?
Output:
Output:
Great question! Data refers to raw facts, measurements, or observations that haven't been processed into meaningful context. Information is data that has been organized, analyzed, and interpreted so it can support decisions or actions. In other words, data is the raw material and information is processed, useful knowledge.
Chat Format
Phi-2's chat format is standard. Here's a simple example:
Prompt:
Human: Hello, who are you?
AI: Greetings! I am an AI research assistant. How can I help you today?
Human: Can you tell me how black holes are formed?
AI:
Output:
Black holes can form when a massive star exhausts its fuel and collapses under its own gravity. The resulting object becomes extremely dense and warps spacetime around it, creating a gravitational pull so strong that nearby matter -- and even light -- cannot escape...
Code Format
Here's a code generation prompt template that provides the model with a function name:
Prompt:
def multiply(a,b):\n
Note that the model was trained on a limited set of Python code examples and libraries, so there are some limitations in code generation capabilities and language support. If you have specific code generation needs, try providing more detailed context or guidance.
Phi-2 Limitations
Summary of reported Phi-2 limitations:
- Like other models, Phi-2 can generate inaccurate code and statements.
- Phi-2 isn't instruction-tuned like other models, so it may struggle to follow instructions.
- Training data is primarily standard English, so the model may have difficulty with slang and other languages.
- Phi-2 can also produce social biases and harmful content.
- Phi-2 hasn't been tuned, and tends to generate verbose responses, sometimes producing irrelevant extra text. The authors attribute this to the textbook-heavy nature of the training data.
Image source: Microsoft Research